| On this page |
Overview ¶
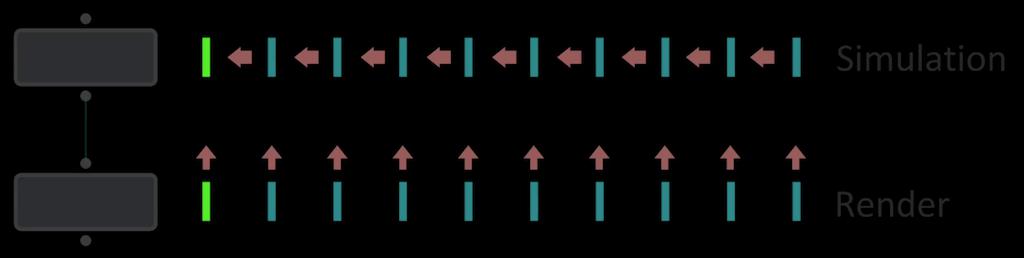
In a TOP network, some work items can be dependent on other jobs, meaning the first item must finish before the second item can begin. This is sometimes referred to as a child item being dependent on a parent item.
-
When an new item is generated from an incoming item in a processor node, the new item automatically is dependent on the incoming item.
-
Downstream items can be dependent on upstream items (for example, you can only render a simulated frame once the geometry is generated), or items can depend on other items in the same node (for example, when you generate a simulation, each frame must wait for the previous frame).
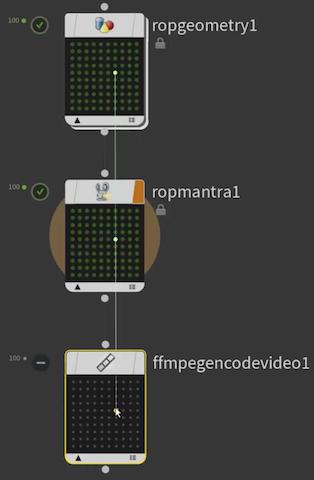
One way to tell you need a partitioner is when a node is obviously generating too much work. For example, generating a video should be one piece of work, not separate work items for each frame. This indicates you need a Wait for All node before the video encode node:
Creating dependencies ¶
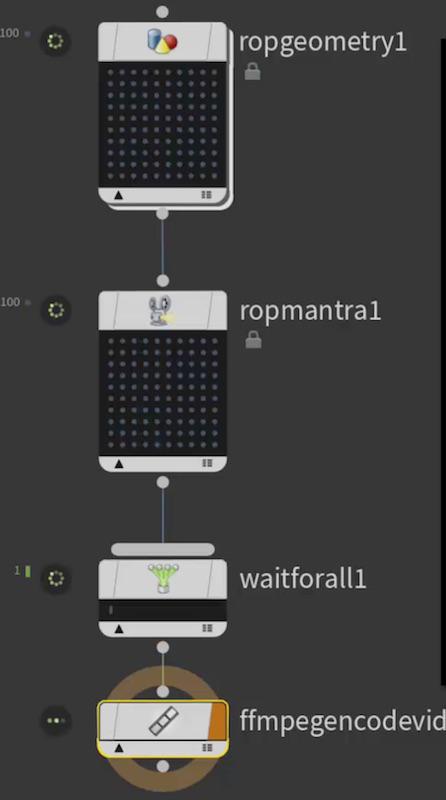
Often you need to “teach” the network about dependencies (that is, where to wait for upstream work to finish before proceeding), using a partitioner node.
Waits for all input work items to finish. This is commonly used at the end of a “pipeline” step (when we know the next step needs all the inputs to be ready). For example, you must wait for all frames to render before generating a video file.
Wait for All is most commonly used at the end of the entire network to gather together all upstream branches (perhaps before some notification nodes).
Waits for all input work items with the same frame number to finish. This is common in rendering and simulation workflows, where you have parallel work generated from input frames, but then need to merge those intermediate results into a “final” frame.
Waits for groups of input work items that have the same value for a certain attribute. This lets you use attributes to set up arbitrary partitions.
For example, you could grab a bunch of file paths with ![]() File Pattern, then group together the paths that share a certain substring.
File Pattern, then group together the paths that share a certain substring.
Partition items ¶
Partitioner nodes create new work items that depend on a set of incoming work items (the work items the parition item is waiting for). These partitions are not necessarily exclusive: you can have multiple partition items depending on the same incoming item.
Similar to how work items created from incoming work items inherit the incoming item’s attributes, partition items inherit the attributes of the incoming items merged into lists. This may be useful in certain workflows, for example you could sum or average lists of numeric attributes from the incoming nodes.
Extracting work items from a partition ¶
A partition work item isn’t actually a “group” containing the items that were merged together, however you can extract the work items as if it was, using the ![]() Work Item Expand node.
Work Item Expand node.
This can be useful in certain workflows where you take advantage of partition nodes (such as ![]() Partition by Attribute) to group work items together based on certain criteria, but then want to continue on doing work on the grouped items, instead of on the merged single partition item.
Partition by Attribute) to group work items together based on certain criteria, but then want to continue on doing work on the grouped items, instead of on the merged single partition item.