| On this page |
|
Overview ¶
Houdini ships with several built-in nodes for running external programs/scripts in TOPs: ![]() ImageMagick,
ImageMagick, ![]() FFmpeg Encode Video,
FFmpeg Encode Video, ![]() ShotGrid Download, and so on. However, you will often need to make your own or other third party scripts/programs usable in TOPs.
ShotGrid Download, and so on. However, you will often need to make your own or other third party scripts/programs usable in TOPs.
You can run external programs from a TOP network in a few ways:
-
You can use a Python Script node and type the script you want to run into the node.
The
 Python Script node automatically creates new work items to run a work script once for each incoming work item. You can access the incoming work item’s attributes in the script, and set output attributes on the outgoing work items based on the work the script does.
Python Script node automatically creates new work items to run a work script once for each incoming work item. You can access the incoming work item’s attributes in the script, and set output attributes on the outgoing work items based on the work the script does.-
Very useful for experimentation, and for “one-off” scripts that do something specific to one particular network.
-
Most convenient option, only requires writing a work script.
-
Not as flexible. If you need to create work items from scratch, or create multiple work items from upstream work items, you need to create a new processor type instead of using the Python Script node.
-
Can’t have a custom user interface.
See writing a one-off script below.
-
-
The
 Generic Generator node generates a new work item to execute a given command line for each incoming work item. You can set this command line to execute a work script. This is effectively the same as the Python Script node but with an external script file instead of having the script embedded in the node.
Generic Generator node generates a new work item to execute a given command line for each incoming work item. You can set this command line to execute a work script. This is effectively the same as the Python Script node but with an external script file instead of having the script embedded in the node. -
You can create a new Python Processor node.
The
Python Processor node lets you write custom Python to generate work items. You can create a digital asset from this node, allowing you to share the new functionality across networks and users.-
Requires more advanced Python coding using the
pdgAPI, as well as writing a work script. -
More flexible: you have full control over generating work items. For example, you can create multiple work items based on incoming items. (You cannot generate fewer work item than are incoming. For that you would create a partitioner.)
-
You can give the node a custom interface using spare parameters, to allow the user to control how the node works.
See making a new processor type below.
-
Python Script will probably be your first option when building a network. If you find you need the greater flexibility of a custom Python Processor, you can still re-use the work script you created for the Python Script node.
Writing a one-off script with Python Script ¶
-
If the work done for each work item is small or localized such that it wouldn’t make sense to schedule it on a process queue or render farm (for example, copying files), you can turn on Evaluate in process to do the work in the main process.
When Evaluate in process is on, you can use the
self(the current pdg.Node object) andparent_item(the upstream pdg.WorkItem that spawned the current work item) variables are available in the work script. -
If Evaluate in process is off, you can set which Python executable to use to execute the script. If you need access to Houdini’s
houmodule, use “Hython”. If the script is pure Python (this includes thepdgjsonandpdgcmdmodules), you can set this to “PDG Python”. The regular Python starts faster than Hython, and doesn’t use a Houdini license. -
Write the script to execute in the Script editor.
For each incoming work item, the node will create a new work item that runs this script. A pdg.WorkItem object representing the current work item is available in the script as
work_item.See how to write a work script for more information.
Keep in mind that (unless Evaluate in process is on) this script might be scheduled to run on a render farm server. Try not to make assumptions about the local machine. See Job API
Making a new processor type with Python Processor ¶
-
In a TOP network, create a
Python Processor node. -
If you know that this node can’t create new work items until upstream work items are finished (that is, it needs to read data on the upstream items to know how many new items to create), set Generate When to “Each Upstream Item is Cooked”. Otherwise, leave it set to “Automatic”.
-
The Command field on the Processor tab doesn’t do anything. It’s meant to be referenced in the generation script as a spare parameter, to set the command line of new work items. Many people find it makes for easier editing to set up the command line in a parameter and reference it, rather than hard-coding it in the script.
-
Add spare parameters to allow the user to control how the node works.
This is much more flexible and convenient than hard-coding values into the Python code. You can continue to refine the interface as you work on the code, adding or removing parameters as you work out the code.
-
Fill in the Generate tab. The callback script on the Generate tab controls what work items the node creates, what attributes the work items have, and the command line run by each work item.
See the help for the generate tab below. See the generate example for one example of a generation callback.
The generation callback is called differently depending on whether the node is static or dynamic.
-
If the node is static, the generate callback is called once. The
upstream_itemslist contains the full list of upstream work items, since generation will only happen after the input node(s) have finished generating. -
If the node is dynamic, the generate callback is called multiple times. The
upstream_itemslist contains at least one cooked work item. If multiple upstream work items finish around the same time PDG will group them together and call the generation logic on that list of work items. In the worst case there will be one generate callback call for each cooked upstream work item, with a input list size of one.If the node is dynamic but you want to wait until all upstream items are available, insert a
 Wait for All node above the Python Processor. Then in the Python Processor node you can access the
Wait for All node above the Python Processor. Then in the Python Processor node you can access the WorkItemobjects inside the partition using:upstream_items[0].partitionItems
Alternatively, you can also change the Generate When parameter from Each Upstream Item is Cooked to All Upstream Items are Cooked.
Note
You should always use the
parentkeyword argument to specify which new work item it generated from which upstream item. This is necessary even if the node is dynamic. -
-
We recommend that the command line run a Python work script. This is more flexible than running an executable directly, and allows the script to report back results.
See the help for writing a work script below.
You can put the work script in a known location in the shared network filesystem, and then use that shared location on the command line.
or
You can put the script somewhere on the Houdini machine, and set it as a file dependency on this node in the File tab. This causes the file to be copied into a directory on each server. Then you can use
__PDG_SCRIPTDIR__on the command line to refer to the shared script directory. (If you create different types of work items calling different wrapper scripts, you can set them as multiple file dependencies.) -
You will usually not need to write a custom script on the Regenerate static tab.
The default implementation dirties work items when any parameters change. This is usually sufficient, but if you want to use more clever logic (for example, checking the
etagof a URL and dirtying the work item if it’s changed), you can implement it on this tab. -
You only need to write a custom script on the Add internal dependencies tab if some work items generated by this node should depend on other new work items generated by this node.
-
If you want to package up the processor as an asset for re-use across users and networks, you can build an asset from a Python Processor.
Building the interface ¶
If you know what you want your new processor to do, you can design the user interface using spare parameters, and then write the code to look up options in the parameters.
Tip
If you later convert the node to an asset, it will automatically use the spare parameters as the asset’s interface.
-
See adding spare parameters for how to add extra “spare” parameters to the node.
Try to give the parameters short but meaningful internal names, so you can refer to them easily in scripts.
-
You can use parameter values to change how the node generates work items, and/or the attributes on work items. See below.
-
When setting default values for parameters:
-
Do not use localized paths as default values.
__PDG_DIR__will expand to the PDG working directory on any machine. -
Use
@pdg_namein file paths to ensure they're unique to each work item. Work item names are unique across the HIP file. This means output files should not overwrite each other unless you store multiple HIP files in the same directory and cook them at the same time.
-
Generating work items ¶
The code to generate work items in on the Generate tab in the onGenerate callback editor. The network runs this code when the node needs to generate work items: for example, when the network starts cooking, or if the user requests pre-generation of static work items.
This code runs in a context with some useful variables defined:
Name |
Type |
Description |
|---|---|---|
|
A reference to the current PDG graph node (this is not a Houdini network node). Any spare parameters on the Python Processor node/asset are copied into this object as pdg.Port objects. You can access them using |
|
|
A reference to the work item holder object for this node. You can use this object’s methods to create new work items. |
|
|
|
A list of incoming pdg.WorkItem objects, or an empty list if there are no incoming items. You can use this list to generate new work items from incoming items, if that’s how your node works. |
|
This is set to Advanced scripts might use this to check certain pre-conditions when the node generates dynamically. For most users, you can ignore the value of this variable. |
The following describes how to accomplish common tasks in the Python code:
| To... | Do this |
|---|---|
|
Generate a new work item in the generation callback |
|
|
Set attributes on a newly created work item |
A work item’s new_item = item_holder.addWorkItem(index=0) new_item.setStringAttrib("url", "http://...") |
|
Read the values of spare parameters |
The node copies the values of any spare parameters into the You can supply a Important: A work script does not (usually) have access to the parameter ports, so if you want the parameters to influence how work gets done, you must copy evaluated parameter values into work item attributes: new_item = item_holder.addWorkItem(index=0) # Evaluate the URL parameter in the context of this new work item url = self["url"].evaluateString(new_item) # Put the evaluated value on the work item as an attribute new_item.setStringAttrib("url", url) In general, parameters should be evaluated after a work item is created, using the new work item as the context in which the parameter is evaluated. This is so the user can use expressions such as Of course, there may be parameters you must evaluate without a work item context, for example a parameter that specifies how many work items to create. |
|
Specify the command line to run |
Use the new_item = item_holder.addWorkItem(index=0) new_item.setCommand("__PDG_PYTHON__ /nfs/scripts/url_downloader.py") You can reference the node’s Command parameter instead of hard-coding the command line here: command_line = self["pdg_command"].evaluateString() new_item.setCommand(command_line)
Tip If you specify a work script, you don’t need to pass work item information on the command line, you can look it up in the script using Python helper functions (see writing a work script). If you want to pass other types of information/options to the script, you can use simple (positional arguments and |
|
Signal a warning or error to the user |
Raise import pdg # Get the number of new items to create for each incoming item per_item = self["peritem"].evaluateInt() if per_item > 16: # Too many! raise pdg.CookError( "Can't create more than 16 items per incoming item" ) # Go on to create new items... |
Example generation script ¶
For example, we might be building a processor that downloads files from URLs using the curl utility program. If there are upstream items, we’ll generate new work items from them, otherwise we’ll create a single new item “from scratch” and set its attributes from the node’s parameters.
Add spare parameters ¶
For a URL downloading node, we might add two spare parameters: one to set the URL to download, and one to set the file path to download to.
Internal name |
Label |
Parameter type |
|---|---|---|
|
URL |
String |
|
Output File |
String |
Remember that the user can use @attribute expressions in these fields to change the parameter values based on attributes of the current work item.
Generation script ¶
Enter the following in the onGenerate callback editor on the Generate tab:
# Define a helper function that evaluates parameters and copies the values # into a work item's attributes def set_attrs(self, work_item): # Evaluate the parameter ports in the context of this work item url = self["url"].evaluateString(work_item) # URL to download outputfile = self["outputfile"].evaluateString(work_item) # Set attributes on the new work item work_item.setStringAttrib("url", url) work_item.setStringAttrib("outputfile", outputfile) # Set the command line that this work item will run work_item.setCommand('__PDG_PYTHON__ __PDG_SCRIPTDIR__/url_downloader.py') if upstream_items: # If there are upstream items, generate new items from them for upstream_item in upstream_items: # Create a new work item based on the upstream item new_item = item_holder.addWorkItem(index=upstream_item.index, parent=upstream_item) # Set the item's attributes based on the parameters set_attrs(self, new_item) else: # There are no upstream items, so we'll generate a single new work item new_item = item_holder.addWorkItem(index=0) # Set the item's attributes based on the parameters set_attrs(self, new_item)
Test generation ¶
With the generation script above, you should be able to test the Python Processor node by setting the output flag on it and choosing Tasks ▸ Generate Static Work Items. Try it with no input and with the input connected so it has upstream work items. Open the task graph table to check the attributes on the generated items.
Write a work script ¶
Now you just have to implement the url_downloader.py script you referenced in the work items' command line. See writing a work script below for more information.
Writing a work script ¶
When a work item is actually scheduled on the local machine or render farm, and is run, it executes a command line. This can be a plain command line running an executable, but for flexibility and convenience we recommend you have the command line run a Python work script. This script lets you access attributes on the work item to influence execution, and set output attributes on the work item based on any files generated by the script.
In a Python Script node, the work script is what you type in the Script field, and the node automatically sets the work items it generates to execute it. In a Python Processor node, you should create this script externally (in the network filesystem shared with the render farm), and set the work items you create to execute it.
Differences between Python Script and external script files ¶
-
In the Python Script node, the
work_itemvariable automatically contains a pdg.WorkItem object representing the current work item.If Evaluate in process is on,
selfis a pdg.Node representing the current graph node, andparent_itemis a pdg.WorkItem object representing the work item that spawned the current work item. -
In an external wrapper script, you can get a pdg.WorkItem object representing the current work item using this header code:
import os from pdgjson import WorkItem # The current work item's name is available in an environment variable, # and will be used automatically to construct an out of process # representation of the work item work_item = WorkItem.fromJobEnvironment()
Note
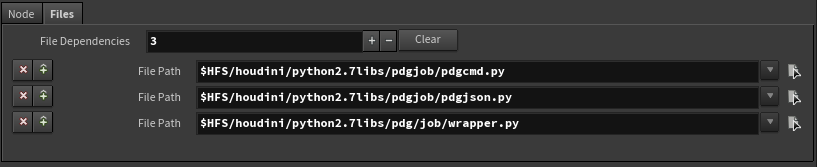
pdgcmd.pyandpdgjson.pywill be automatically added as file dependencies if a Python Processor node is saved to a digital asset. If you want to use them otherwise, you need to addpdgcmd.pyandpdgjson.pyas file dependencies. They can be found at:-
$HHP/pdgjob/pdgcmd.py -
$HHP/pdgjob/pdgjson.py
If your work script is executing as Evaluate in process, you can use
from pdgjob import pdgcmd, otherwise you can useimport pdgcmd, since that module will have been copied to the scripts folder of the work item’s working directory. -
-
In the Python Script node, the work item object and attribute accessors are automatically available without import. In an external work script, you can import them from
pdgjsonand instantiate the work item from the job environment. An out-of-process work item has a subset of the regular work item Python API. It can only be used to access or modify attributes, and add output files.# Don't need to do this import in a Python Script node, # only in an external job script from pdgjson import WorkItem work_item = WorkItem.fromJobEnvironment() # The following code will work both in-process and out-of-process. When # running out-of-process, the work_item is a light-weight implementation # of the standard pdg.WorkItem API that supports basic attribute and output # file access url = work_item.stringAttribValue("url") # Adds an output file to the work item work_item.addOutputFile("myfile.txt", "file/text")
-
It is possible to set attribute values on work items from an external script file using the regular attribute API. The changes are automatically transmitted back to PDG and applied to the work item in the graph:
from pdgjson import WorkItem work_item = WorkItem.fromJobEnvironment() work_item.setIntAttrib("outputsize", 100)
-
Python object attributes are serialized using the Python module specified in the
PDG_PYATTRIB_LOADERenvironment variable, or using the built-inreprfunction is the variable is unset. The host Houdini process will deserialize them using the same module:from pdgjson import WorkItem work_item = WorkItem.fromJobEnvironment() custom_data = {'key': [1,2,3], 'second_key': (4,5)} work_item.setPyObjectAttrib("custom_data", custom_data)
-
In an external work script, it may sometimes be easier to pass extra, untyped information from the work item to the script as command line options. The work script then decodes the options on its command line
Doing work ¶
-
A work script might do all the work in Python, or it might just be a “wrapper” that calls an external executable.
For example, to download a file from a URL, you could use the built-in Python libraries, or call the external
curlutility.import requests from pdgjob import pdgcmd # When running out of process with system Python, pdgcmd must # be imported directly from PDG's working directory instead of # from HFS. # # import pdgcmd url = work_item.stringAttribValue("url") outfile = work_item.stringAttribValue("outputfile") local_outfile = pdgcmd.localizePath(outfile) r = requests.get(url, allow_redirects=True) open(outfile, "wb").write(r.content)
or
import subprocess from pdgjob import pdgcmd # When running out of process with system Python, pdgcmd must # be imported directly from PDG's working directory instead of # from HFS. # # import pdgcmd url = work_item.stringAttribValue("url") outfile = work_item.stringAttribValue("outputfile") local_outfile = pdgcmd.localizePath(outfile) rc = subprocess.check_call( ["curl", "--output", outfile, "--location", url] )
-
If you get a file path from a work item, you can use
pdgcmd.localizePath()to make sure to expand placeholders and environment variables to make the path specific to this machine. -
If you are generating an intermediate result file in the script and want to put in the temp directory, you can access the directory path using
os.environ["PDG_TEMP"]. -
If the script/executable exits with a non-zero return code, the work item is marked as an error. Any output to
stdoutorstderris captured on the work item. -
To run external programs from the work script, use the following functions in Python’s subprocess module. These functions replace several older, less capable or less secure functions in the Python standard library.
subprocess.call()Runs a command line and returns the return code.
subprocess.check_call()Runs a command line and raises an exception if the command fails (non-zero return code).
subprocess.check_output()Runs a command line and returns the output as a byte string. Raises an exception if the command fails (non-zero return code).
-
Using the
check_functions makes your script automatically exit with a non-zero return code, and print the OS error as part of the exception traceback (for example,No such file or directory). If you want more control you can catch the exception and print your own error messages tostderr. -
These functions can take a full command line string as the first argument, however the best practice for security and robustness is to pass the commands, options, and file paths as a list of separate strings:
import subprocess rc = subprocess.call(["curl", "--config", configfile, "--output", outfile, url])
Using separated strings helps catch errors and prevents certain types of attacks. Another benefit is that you don’t have to worry about escaping characters (such as spaces) in file names.
-
These functions have arguments to let you pipe an open file to the
stdinof the command, and/or pipe the command’sstdoutto an open file. You can specifyshell=Trueif the command must be run inside a shell.
-
The Job API - Reporting results ¶
The Job API can be used to report output files and attributes back to the running work item in PDG.
Environment variables ¶
The system runs a work item’s command line in an environment with a few useful environment variables set.
-
In an external script run by a TOP scheduler, you can access the environment variables in the usual way for the given language, for example
os.environ["PDG_DIR"]in Python or$PDG_DIRin shell.
PDG_RESULT_SERVER
A string containing the IP address and port of server to send results back to. You usually don’t need to look this up manually, for example you can call pdgcmd.addOutputFile(file_path) and it will automatically get this value from the environment.
PDG_ITEM_NAME
The name of the current work item. You can use this with pdgjson helper functions to look up the work item’s data based on its name, and build a WorkItem object from the data.
import os # The current work item's name is available in an environment variable item_name = os.environ["PDG_ITEM_NAME"] # Look up the work item data by name and build a WorkItem object from it work_item = WorkItem.fromFile(getWorkItemJsonPath(item_name)) # This is equivalent to using WorkItem.fromJobEnvironment function: same_item = WorkItem.fromJobEnvironment()
PDG_INDEX
The index of the current work item.
PDG_DIR
The TOP network’s working directory, as specified on the Scheduler node.
PDG_TEMP
A shared temporary file directory for the current session, inside the working directory. The default is $PDG_DIR/pdgtemp/‹houdini_process_id›.
PDG_SCRIPTDIR
A shared script directory, inside the temp directory. Script files are copied into this directory if they are listed as file dependencies. The default is $PDG_TEMP/scripts.
Alternatively, you can simply put scripts in known locations in the shared network filesystem.
Create an asset from a Python Processor node ¶
Once you have a Python Processor working the way you want, you can convert it to an asset to make it easier to re-use.
-
Select the Python Processor. In the parameter editor, click Save to digital asset.
-
Fill out the dialog and click Accept.
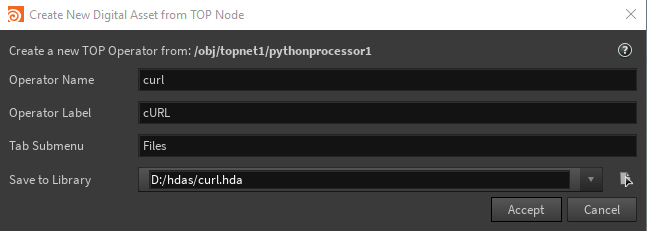
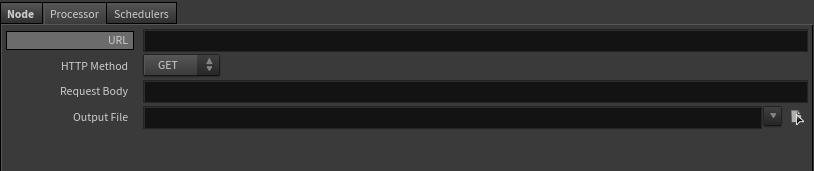
The new asset type will automatically use any spare parameters on the Python Processor as parameter interface on the Processor tab.
File dependencies are automatically added for the support modules.
-
You can continue to edit the asset’s parameter interface. However, note the following:
-
If you edit the interface and Houdini asks you what to do with spare parameters, click Destroy all spare parameters.
-
If you don’t reference the Command parameter to set the command line for work items, you should hide or delete it from the interface so it doesn’t cause confusion.
-