| On this page |
|
概要 ¶
カスタムスケジューラノードを作成すれば、ビルトインのスケジューラノードで対応していないスケジューラソフトウェアにワークを送信することができます。 カスタムノードであれば、独自にワークのスケジュールを組んだり(例えば、独自のスケジューリングアルゴリズムを使用したい)、サードパーティ製または内製のスケジューラのAPIにアクセスすることができます。
Warning
カスタムスケジューラを作成するには、Pythonプログラミングの経験とインテグレートしたいスケジューラソフトウェアの知識が必要になります 。 Pythonコードで何を実装するべきなのか、何が効率的で効率的でないのかは、スケジューラソフトウェアに完全に依存するので、ここでは手順の説明をすることはできません。 インテグレーションのスニペットを記述するには、スレッドプログラミング、サーバーの実行、他にも初心者向けでないプログラミングが必要になります。
また、現在の実装はあくまで 原案 と思ってください。今後のバージョンで修正/変更される予定です。 カスタムスケジューラの実装を試してみた結果を私たちにフィードバックしていただくことを歓迎しております。 この領域では、それが今後の励みになります。
カスタムスケジューラの作り方 ¶
カスタムスケジューラを実装するには、以下の手順を踏みます:
Python Scheduler TOPを使用しない方法 ¶
-
HOUDINI_PATH内に
pdg/typesディレクトリ(例えば、~/houdini18.5/pdg/types)を作成します。 -
新しいスケジューラにちなんだ名前のディレクトリを作成して__init__.pyファイルを追加(例えば、
~/houdini18.5/pdg/types/customscheduler/__init__.py)することで、カスタムスケジューラ用のPythonパッケージを作成します。 -
その新しいパッケージディレクトリ内にカスタムスケジューラ用のPythonモジュール(例えば、
~/houdini18.5/pdg/types/customscheduler/customscheduler.py)を作成します。 -
その
customscheduler.py内部でスケジューラタイプを実装します。すぐにでも何かを動作させられるように、最初のうちは私どもの内部スケジューラをサブクラス化するのが便利かと思います。以下には、ジョブを連続生成する Local Schedulerの単純な例を載せています。
Local Schedulerの単純な例を載せています。
import os import shlex import subprocess import sys import tempfile import six.moves.urllib.parse as parse # LocalSchedulerクラスをimportできるように、$HFS内のスケジューラタイプフォルダをPYTHONPATHに追加します(この時点ではLocalSchedulerクラスはまだ読み込まれません)。 import pdg sys.path.append(os.path.expandvars("$HFS/houdini/pdg/types/schedulers")) from local import LocalScheduler sys.path.pop() from pdg.utils import expand_vars class CustomScheduler(LocalScheduler): def onSchedule(self, work_item): print("onSchedule {}".format(work_item.name)) item_command = work_item.command item_id = work_item.id item_command = self.expandCommandTokens(item_command, work_item) job_env = self._generateEnvironment(work_item, 0) # 必ずディレクトリが存在するようにし、ワークアイテムをシリアライズします。 self.createJobDirsAndSerializeWorkItems(work_item) # ジョブ変数を置換してから、Houdini変数($HFSなど)を置換します。 item_command = expand_vars(item_command, job_env) item_command = os.path.expandvars(item_command) self.workItemStartCook(item_id, -1) # shlexを使用したいので、コマンド内にはunicodeが含まれないようにします。 if sys.version_info.major < 3: item_command = item_command.encode('ascii', 'ignore') argv = shlex.split(item_command) try: log = subprocess.check_output(argv, shell=True, env=job_env) with tempfile.NamedTemporaryFile(delete=False) as f: f.write(log) work_item.setStringAttrib("custom_log", f.name) self.workItemSucceeded(item_id, -1, 0) except subprocess.CalledProcessError: self.workItemFailed(item_id, -1, 0) return pdg.scheduleResult.Succeeded def getLogURI(self, work_item): log = work_item.stringAttribValue('custom_log') if log: return parse.urlunparse(('file','', log, '', '', '')) return ''
-
__init__.py内部で、新しいスケジューラタイプを登録します。
from . import customscheduler def registerTypes(type_registry): print("Registering customscheduler") type_registry.registerScheduler(customscheduler.CustomScheduler, label="Test Custom Scheduler")
-
PDGは初期化する時に、新しいスケジューラタイプを登録するcustomschedulerパッケージをimportするようになります。PDGはTOPsのTabメニューに
customschedulerを表示します。
Tip
環境変数でHOUDINI_PDG_TYPE_ERROR=2を設定すると、PDGタイプが読み込まれた時にそれらのタイプに関する追加ログ情報を取得することができます。
Python Scheduler TOPを使用した方法 ¶
-
TOPネットワーク内に
Python Schedulerノードを作成します。このノードには、スケジューラの挙動を定義するコールバック関数用のフィールドが備わっています。 このノードは、他のスケジューラと同様に動作し、コールバック関数フィールドに入力されたPythonコードを評価して実行します。 これは、作業ネットワーク内でスケジューラコードを試行することができて非常に便利です。
-
このノードのタブで色々なPythonスニペットを記入する方法に関しては、以下のコールバックの実装方法を参照してください。
Scheduler TOP ¶
-
ユーザ側でノードの挙動を制御できるようにするためにSpareパラメータを追加します。
このようにした方が、Pythonコード内で値をハードコーディングするよりも非常に柔軟性があり便利です。 コードを記述しつつインターフェースを改良し、コードが記述し終わったらパラメータを追加/削除することができます。
以下のカスタムスケジューラにパラメータインターフェースを追加する方法を参照してください。
-
スケジューラが正しく動作すれば、他のユーザや他のネットワークで使用できるように、そのスケジューラをデジタルアセットに変換することができます。また、これによって個々のTOPノードがスケジューラのパラメータをオーバーライドすることができます(Python Schedulerインスタンスをオーバーライドすることはできません)。
スケジューラの実装方法 ¶
オーバーライドできるコールバックに関しては、スケジューラノードのコールバックを参照してください。
Initialization and Cleanup > StartとStop ¶
Initialization and Cleanup タブのPythonスニペットを使って、最初にスケジューラを起動した時に実行させるコード、TOPネットワークがクックを開始した時に実行させるコード、ネットワークがクックを停止した時に実行させるコード、スケジューラがもはや不要になった時に実行させるコードを記述します。
この作業ディレクトリは、TOP Networkのコードが実行されるディレクトリで、通常では生成ファイルが保存される場所です。
ファームセットアップでは、この作業ディレクトリを共有ネットワークファイルシステム上にしてください。
PDGは、作業ディレクトリのlocalパス、さらに、remoteパスも知っている必要があります。
localパスは、ユーザのファイルシステム上の有効なパス(ネットワークがクックする場所)で、remoteパスはリモートレンダーファームホスト上で有効なパスである必要があります。PDGで指定されたパスを使って、localとremote間のファイルパス変換が行なわれます(それぞれlocalize、delocalizeと呼びます)。
localとremoteのパスを生成/変換するコードは、スケジューラによって異なります。
例えば、スケジューラソフトウェアには、共有ディレクトリを検索するための独自のAPIが用意されていたり、システム環境変数(例えば、$REPO_DIR)を設定する必要があることもあります。
Python Schedulerノードには Working Directory パラメータが備わっており、コード内でself["pdg_workingdir"].evaluateString()を使用することで、そのパラメータにアクセスすることができます。
慣例として、このパラメータには、localのフルパス、または、ファームファイルシステムのマウントポイントを基準とした相対パスのどちらかを指定します。
Scheduling > Schedule ¶
これは、ジョブのスケジューリングを行なう“実際のワーク”を実行する重要なメソッドです。
このメソッドは、ノードがワークアイテムを処理してスケジュールを組む際にコールされます。
このメソッドは、pdg.WorkItemオブジェクトをwork_itemとして受け取ります。
WorkItemデータを受け取って、それを使ってインテグレートしたい独自システム内でスケジュールが組まれたジョブを作成できるように、ここには スケジューラ特有の ロジックを実装しなければなりません。
そのロジックには、特定の変数が定義された環境でコマンドラインを走らせたり、依存ファイルをコピーしたり、スケジューラAPIをコールするといった処理が必要になります。
-
command文字列アトリビュートには、ジョブを実行するコマンドラインを格納します。 -
スケジューラが後でジョブを照会できるようにジョブ毎の固有なキーを必要/受け取る場合には、
WorkItem.nameを使用してください。 -
ジョブがスケジュールに組まれたら(または、エラーに遭遇したら)、このスニペットはpdg.scheduleResult値を返すようにしてください。
Scheduling > Ticking ¶
ファームスケジューラのAPIのポーリング(問い合わせ)を使ってジョブの進捗を監視したいことが多いです。 これは、onTickコールバックの実装によって行なうことができます。 このonTick関数の戻り値のpdg.tickResultは、PDGにバインドの状態を知らせます。
例えば、ファームスケジューラの接続が切れて復旧できなくなった場合にSchedulerCancelCookを返すことができます。
SchedulerBusyとSchedulerReadyは、onScheduleコールバックを制御できる準備が整っているかどうかをPDGに知らせることができます。
これを利用することで、サーバーや他のリソースの負荷を制御しながらフェームへのワークアイテムの投入を制限することができます。
tickPeriodとmaxItemsのスケジューラ系ノードのパラメータを使用することで、onTickとonScheduleのコールの頻度を設定することができます。
Scheduling > Schedule static ¶
onScheduleStaticを参照してください。 これは、静的クックモードでのみ利用し、現在のところTOP UIには露出されていません。
Job Status Notification ¶
ジョブのステータスが変更されたことをTOPネットワークに伝えるためのメソッドを必ず実装しなければなりません。
スケジューラソフトウェアから通知を受け取る方法は、実装によって異なります。
しかし、Houdiniには、再利用できそうなコードをバインドしたいくつかのスケジューラのPython実装が同梱されています。
$HFS/houdini/pdg/types/schedulersと$HHP/pdgのソースコードを調べることを強く推奨します。
スケジューラがジョブのステータスの変更があったかどうかをポーリング(問い合わせ)する必要がある場合、onTickメソッドでポーリングする必要があることに注意してください。
あなたが使用しているスレッドまたはコールバックで、常にself(Schedulerオブジェクト)を参照しなければならないことを忘れないでください。
Note
pdg.Scheduler通知メソッドには、ジョブを作成したオリジナルのワークアイテムのid整数とindex整数を渡す必要があります。
この場合のindexのことをバッチサブインデックスと呼ぶことに注意してください。
非バッチジョブでは、indexに-1を渡してください。
あなたのスケジューラソフトウェアが、それらの引数をジョブにデータとして追加することができる場合、あなた自身でそれらの引数を何かしらの方法(例えば、スケジューラソフトウェアの内部ジョブIDを(id, index)タプルにマッピングしたPython辞書をメモリ内に保持することができます)で保存する必要があります。
しかし、スケジューラソフトウェアがジョブのステータスの変更を検知したら、pdg.Scheduler (self)の以下のメソッドのどれかがコールされます:
self.onWorkItemStartCook(id, index, clear_outputs=False)
以前にキューに登録したジョブが実行を開始した時に、このメソッドがコールされます。
self.onWorkItemSucceeded(id, index, cook_duration)
ジョブが成功したら、このメソッドがコールされます。
idとindexの引数に加えて、cook_duration引数を渡します(ジョブが実行された浮動小数点の秒数の期間)。
self.onWorkItemFailed(id, index)
ジョブが成功したら、このメソッドがコールされます。オリジナルのワークアイテムのidとindexを渡します。
self.onWorkItemCanceled(id, index)
ユーザが手動でジョブをキャンセルしたら、このメソッドがコールされます。
オリジナルのワークアイテムのidとindexを渡します。
self.onWorkItemAddOutput(id, index, path, tag, checksum, active_only=False)
ワークアイテムが出力ファイルを生成する時にコールされます。
pathはそのファイルパスの文字列、tagはファイルタグ文字列(例えば、file/geo)、checksumは整数値です。
active_onlyがTrueの場合、PDGは、既にクックを終了したワークアイテムへのコールを除外し、それらのワークアイテムにファイルを追加しなくなります。
Scheduling > Submit as job ¶
これは、ユーザがTOPネットワーク全体を単一ジョブとして投入した時にコールされます。 これは、あなたが実装するかどうか選択自由なオプションの機能です。 例えば、HQueue Schedulerには Submit Graph as Job ボタンがあります。
-
graph_file変数には、クックするTOPネットワークを含んだHIPファイルのパスが格納されます。このパスは、そのTOPネットワークをクックするマシンの作業ディレクトリを基準としたパスです。 -
node_path変数には、HIPファイル内のクックするTOPネットワークノードのノードパスが格納されます。
もし あなたがこの機能に対応したい場合、あなたのコード次第では、Houdiniを実行するスクリプトジョブを作成して、それをスケジュールに組んで、指定したHIPファイルを読み込んで、指定したネットワークをクックすることができます。
Tip
HOMを使ってHoudiniにTOPネットワークをクックさせるには、まず親ネットワークを検索し、そのネットワーク内からディスプレイフラグが有効になっているTOPノードを検索し、そのTOPノードのhou.TopNode.cookWorkItemsメソッドをコールします。 詳細は、/tops/cooking.html#cookhomを参照してください。
Shared servers > Transfer file ¶
Logging ¶
これらのスニペットは、work_item変数にpdg.WorkItemオブジェクトを格納します。
ワークアイテムのデータ(必要に応じてスケジューラのAPIも一緒に)を使用して、それに該当するジョブのログ/ステータスのページの場所を特定することができれば、TOPインターフェース上にそのログ/ステータスをワークアイテムの情報の一部として表示することができます。
Log URI
getLogURIを参照してください。
ワークアイテムに関しては、システムがそれに該当するジョブの出力/エラーのログを表示する時に取得可能なURLを返します。
共有ネットワークファイルシステム上のファイルを参照している場合には、file:URLが返されます。例えば、file:///myfarm/tasklogs/jobid20.logです。
スケジューラがfile:URLに対応していない場合は、空っぽの文字列を返します。
Status URI
getStatusURIを参照してください。
ワークアイテムに関しては、システムがそれに該当するジョブのステータスを表示する時に開くことが可能なURLを返します。
通常では、スケジューラのウェブインターフェース内のジョブのステータスのページへのhttp:リンクが返されます。
スケジューラがhttp:URLに対応していない場合は、空っぽの文字列を返します。
ユーザインターフェースの作り方 ¶
Spareパラメータ とは、既存ノードのパラメータインターフェースに追加する“ユーザ”パラメータのことです。 このパラメータを追加することで、スケジューラにユーザ側で設定可能なオプションを追加することができます。 このノードを後でアセットに変換すれば、それらのSpareパラメータがアセットのインターフェースの一部として自動的に使用できるようになります。
-
Spareパラメータを追加する方法に関しては、Spareパラメータを参照してください。
-
このノードのPythonコードスニペットの中に
selfを使用すれば、このスケジューラを表現したpdg.Schedulerインスタンス(これは、Houdiniネットワークノードオブジェクト ではありません )を参照することができます。Python Processorノード/アセット上のすべてのSpareパラメータは、このオブジェクト内にpdg.Portオブジェクトとしてコピーされます。
self["‹parm_name›"]を使用することで、それらのパラメータにアクセスすることができ、Port.evaluateFloat(),Port.evaluateInt()などを使用することで、それらの値を読み込むことができます。# このノードの"url"パラメータからコピーされた値を取得します。 url = self["url"].evaluateString()
-
スクリプトからそれらのパラメータを簡単に参照できるようにするために、それらのパラメータ名を短く、且つ、意味のわかる内部名を付けるように心がけてください。
-
個々のノードがパラメータをオーバーライドできるようにするには: Spareパラメータ編集インターフェース内で、そのパラメータに
pdg::schedulerタグを付けます。 このタグは、パラメータがスケジューラジョブパラメータであり、個々のノードでオーバーライドできる事をPDGに示します。 これらのパラメータは、 Node Properties メニューにも追加されているはずなので、ユーザーは簡単にどのパラメータがオーバーライド可能なのか知ることができ、それらの値をオーバーライドすることができます。 詳細は、Schedulers Propertiesフォルダの追加セクションを参照してください。-
スケジューラのオーバーライドの使い方の詳細は、スケジューラのオーバーライドを参照してください。
-
現在のところ、このタグの値は使用しません。システムは、
pdg::schedulerという名前のタグが存在するかどうかのみをチェックします。 -
これは、ノードをアセットに変換した場合にのみ動作することに注意してください。Python Schedulerインスタンスのパラメータをオーバーライドすることはできません。
Note
個々のノードでオーバーライド可能なパラメータを評価する時、必ず以下のメソッドを使用してください:
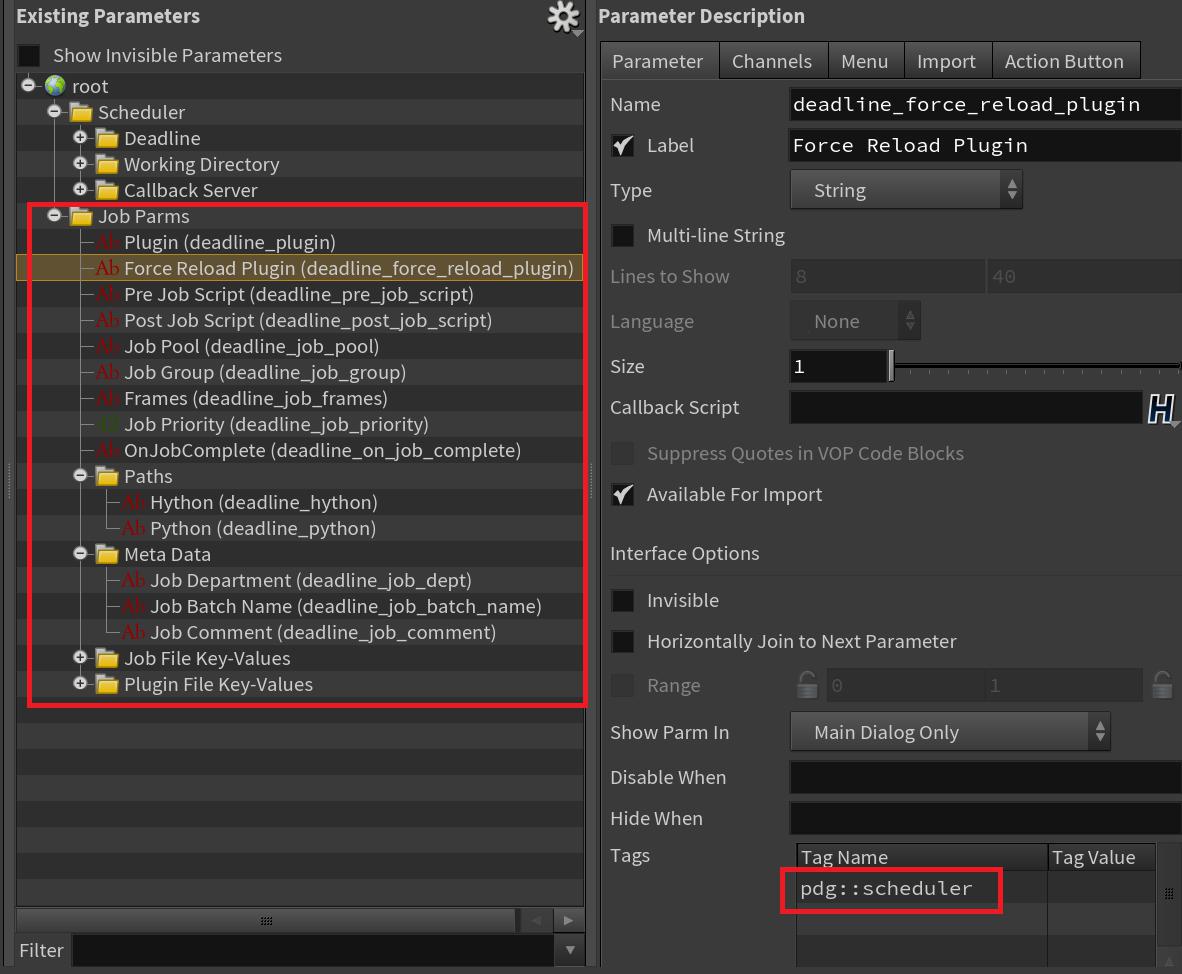
-
Scheduler Propertiesフォルダの追加 ¶
すべてのビルトインスケジューラでオーバーライド可能なスケジューラプロパティはScheduler Propertiesフォルダに入っています。
スケジューラプロパティの使い方に関する詳細は、スケジューラオーバーライドドキュメントを参照してください。
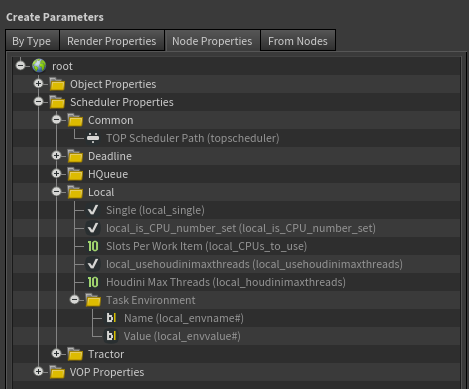
ユーザーがカスタムスケジューラのスケジューラパラメータをもっと簡単にオーバーライドできるようにしたいのであれば、
オーバーライド可能なスケジューラプロパティをScheduler Propertiesフォルダ構造に追加してください。
これをするには、それらのスケジューラプロパティをtopscheduler.user.dsという名前のファイルに追加してください。
このtopscheduler.user.dsファイルは、ユーザーのHOUDINI_PATHのどこにでも配置することができます。
topscheduler.user.dsファイルは、スケジューラのオーバーライド可能なプロパティの定義を含んだダイアログスクリプトファイルです。
Tip
カスタムスケジューラ用のダイアログスクリプトを作成するには、以下の手順に従ってください:
-
Houdiniを起動し、
/tasks/topnet1にカスタムスケジューラノードを配置します。 -
以下のHythonコードを実行します:
open("topscheduler.user.ds", "w").write(hou.node("/tasks/topnet1/foo").parmTemplateGroup().asDialogScript(full_info=True))
-
そのファイルから、スケジューラプロパティでない且つ個々のノードでオーバーライド不可なパラメータを削除します。
-
Commonフォルダ下にすべてのプロパティを配置したいのであれば、
parmtag { spare_category "foo" }をすべてのパラメータ定義に追加してください。fooはカスタムスケジューラのカテゴリに置換してください。そのカテゴリがpdg.TypeRegistry.registerSchedulerに渡された引数に合致します。
カスタムスケジューラの使い方 ¶
Python Schedulerインスタンスまたはカスタムスケジューラアセットを、TOPグラフ全体(つまり、すべてのワークアイテム)または特定のノードから生成されたワークアイテムのみに対して、デフォルトのTOPスケジューラとして設定することができます。
-
デフォルトのTOPスケジューラとして設定するには、TOP Networkノードを選択して、 Default TOP Scheduler をカスタムスケジューラノードに変更します。
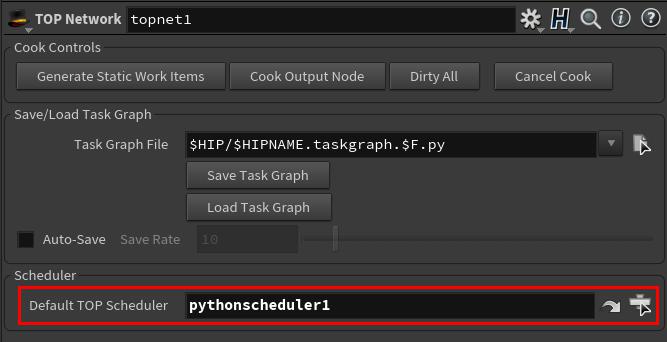
-
特定のTOPノードに対して設定するには、そのTOPノードを選択して、 Override TOP Scheduler をカスタムスケジューラノードに設定します。
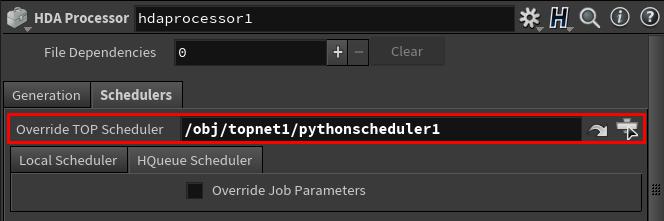
これによって、TOP NetworkノードまたはTOPノードをクックすると、カスタムスケジューラを使ってワークアイテムが処理されるようになります。
完全に静的なクック ¶
PDGは、PDGグラフのクックの時間依存解決とワークアイテムスケジュールの処理をするように設計されています。 しかし、多くの典型的なファームセットアップ(例えば、 Tractor )では、ジョブは1つの単一な階層的表現として指定するのが通例で、そのようなジョブはクックの開始時に静的だと判定されます。 一般的に以下のようにPDGグラフを扱うのが簡単ではない理由がたくさんあります:
TOPグラフでステータスの変化を表示できるようにしたいのであれば、ジョブが結果とステータスの変化を報告できるように、実装でコールバックサーバーを準備する必要があります。
他にも、ジョブスクリプトが実行された時に、そのジョブスクリプトでJSON表現が利用できる、すべてのワークアイテムをシリアライズする必要があります。
さらに、すべてのTOPノードがこのクックモードに対応しているわけではなく、ファームスケジューラを扱う上でいくつかカスタマイズが必要になる場合があります。
例えば、![]() ROP Fetchや他のROPベースのノードは、
ROP Fetchや他のROPベースのノードは、![]() ROP Fetch
ROP Fetch cookwhenがAll Frames are Readyに設定されていない場合にバッチを実行した時にコールバックサーバーをポーリング(問い合わせ)します。
バッチアイテムによるフレーム単位のディペンデンシーを表現することができない場合があります。
上記の理由から、PDGグラフから完全に静的なジョブを生成しようとするのは推奨しません。
静的なCookのハイブリッドな手法 ¶
完全に静的なジョブの代わりに、最終的に実行されるすべての子Taskを持ったファームジョブを 保留 状態のプレースホルダーとして事前に収集することが可能です。 次に、PDGクックが通常どおりに進むと、カスタムスケジューラは、それらのジョブがonScheduleコールバックを介して準備が整った時に、それらのジョブを アクティブ化 します。
この手法だと、ファーム管理者は、静的なジョブ表現と同様にクックの全体像を事前に把握することができます。
ジョブを事前に収集できるようにするために、カスタムスケジューラは、クックの開始時に静的に生成されたPDGタスクグラフを検査する必要があります。 このタスクグラフはpdg.SchedulerBase.dependencyGraphを使ってアクセスすることができます。 TOPグラフは、タスクグラフを照会する前に完全に生成されている必要があることに注意してください。
以下のサンプルは、指定したTaskグラフからDOTフォーマットグラフを生成する方法について説明しています。 このDOTフォーマットグラフは、Graphvizソフトウェアを使って閲覧することができます。
def taskgraphDOT(scheduler, dotfile=None): import sys dependencies, dependents, ready = scheduler.dependencyGraph(True) outf = open(dotfile, 'w') if dotfile else sys.stdout outf.write("digraph taskgraph {\n") for work_item, children in dependents.items(): if not children: continue child_list = " ; ".join((child.name for child in children)) if len(children) > 1: outf.write("%s -> {%s};\n" % (work_item.name, child_list)) else: outf.write("{} -> {};\n".format(work_item.name, child_list)) outf.write("}") # 目的のスケジューラを取得し、Taskグラフを生成してそのdepグラフを取得します。 node = hou.node('/obj/topnet1/localscheduler') sch = node.getPDGNode() output_node = node.parent().displayNode() output_node.cookWorkItems(block=True, generate_only=True) taskGraphDOT(sch, '/tmp/depgraph.dot')
| See also |