| On this page |
|
概要 ¶
Houdiniには、外部のプログラム/スクリプトを実行するためのビルトインのノード(![]() ImageMagick,
ImageMagick, ![]() FFmpeg Encode Video,
FFmpeg Encode Video, ![]() ShotGrid Downloadなど)がいくつか同梱されています。
とはいえ、独自またはサードパーティ製のスクリプト/プログラムをTOPで利用できるようにしたいことがよくあります。
ShotGrid Downloadなど)がいくつか同梱されています。
とはいえ、独自またはサードパーティ製のスクリプト/プログラムをTOPで利用できるようにしたいことがよくあります。
いくつかの方法で、TOPネットワークから外部のプログラムを実行することができます:
-
Python Scriptノードを使って、そのノードに、実行したいスクリプトをタイプすることができます。
 Python Scriptノードは、入力のワークアイテム毎に1回だけワークスクリプトを実行する新しいワークアイテムを自動的に生成します。
このスクリプト内で、入力のワークアイテムのアトリビュートにアクセスしたり、そのスクリプトが実行するワークに基づいて、出力されるワークアイテムに出力アトリビュートを設定することができます。
Python Scriptノードは、入力のワークアイテム毎に1回だけワークスクリプトを実行する新しいワークアイテムを自動的に生成します。
このスクリプト内で、入力のワークアイテムのアトリビュートにアクセスしたり、そのスクリプトが実行するワークに基づいて、出力されるワークアイテムに出力アトリビュートを設定することができます。-
スクリプトを試してみたり、特定のネットワークに特化した何かの処理を行なう“one-off(1回限りの)”スクリプトには非常に役立ちます。
-
非常に便利なオプションが用意されていて、必要な事はワークスクリプトを記述する事だけです。
-
そんなに柔軟性はありません。ゼロからワークアイテムを生成する必要がある場合、または、上流のワークアイテムから複数のワークアイテムを生成する必要がある場合、Python Scriptノードを使用するのではなくて、新しいプロセッサタイプを作成する必要があります。
-
カスタムユーザインターフェースを用意することができません。
以下のone-off(1回限りの)スクリプトの書き方を参照してください。
-
-
 Generic Generatorノードは、入力のワークアイテム毎に、指定したコマンドラインを実行する新しいワークアイテムを生成します。ワークスクリプトを実行できるように、このコマンドラインを設定することができます。これは、実質的にPython Scriptノードと同じですが、ノードの中にスクリプトを埋め込むのではなくて、外部のスクリプトファイルを使用します。
Generic Generatorノードは、入力のワークアイテム毎に、指定したコマンドラインを実行する新しいワークアイテムを生成します。ワークスクリプトを実行できるように、このコマンドラインを設定することができます。これは、実質的にPython Scriptノードと同じですが、ノードの中にスクリプトを埋め込むのではなくて、外部のスクリプトファイルを使用します。 -
新しいPython Processorノードを作成することができます。
Python Processorノードは、ワークアイテムを生成する独自のPythonコードを記述することができます。このノードからデジタルアセットを生成することで、ネットワークとユーザ間で新しい機能を共有することができます。-
ワークスクリプトを記述するだけでなく、さらに
pdgAPIを使ってもっと高度なPythonコードを記述する必要があります。 -
柔軟性が高いです。つまり、ワークアイテムの生成をフルコントロールすることができます。例えば、入力のワークアイテムに基づいて複数のワークアイテムを生成することができます(入力のワークアイテムよりも 少ない数の ワークアイテムを生成することは できません 。そうしたい場合は、パーティショナーを作成することになります)。
-
Spareパラメータを使ってノードにカスタムインターフェースを追加することで、ユーザ側でノードの挙動を制御することができます。
以下の新しいプロセッサタイプの作り方を参照してください。
-
ネットワークを構築する時は、おそらくPython Scriptノードが最初の選択肢となることでしょう。 カスタムPython Processorを使ってもっと柔軟性が必要になった場合でも、このPython Scriptノードで作成したワークスクリプトは再利用することができます。
Python Scriptノードを使ったone-off(1回限りの)スクリプトの書き方 ¶
-
ワークアイテム毎に処理させるワークが小規模またはローカルで十分で、プロセスキューまたはレンダーファームを使ってスケジュールを組むほどでもない場合(例えば、ファイルのコピー)、Python Scriptノードの Evaluate In Process を有効にすることで、そのワークをメインプロセスで処理させることができます。
Evaluate In Process を有効にすると、ワークスクリプト内で利用可能な
self変数(現行のpdg.Nodeオブジェクト)とparent_item変数(現行のワークアイテムの派生元の上流のpdg.WorkItem)を使用することができます。 -
Evaluate In Process を無効にすると、そのスクリプトの実行に使用するPython実行ファイルを設定することができます。Houdiniの
houモジュールにアクセスする必要があるのであれば、“Hython”を使用してください。そのスクリプトが純粋なPython(これにはpdgjsonとpdgcmdのモジュールを含みます)であれば、ここには“PDG Python”を設定することができます。通常のPythonはHythonよりも高速に起動し、Houdiniライセンスを使用しません。 -
Script エディタ内に、実行するスクリプトを記述します。
このノードは、入力のワークアイテム毎に、このスクリプトを実行する新しいワークアイテムを生成します。現行ワークアイテムを表現したpdg.WorkItemオブジェクトは、このスクリプト内では
work_itemとして利用可能です。詳細は、ワークスクリプトの書き方を参照してください。
( Evaluate In Process が有効でない限り)このスクリプトは、レンダーファームサーバー上で実行されるようにスケジュールが組まれることを忘れないでください。 ローカルマシンを想定しないようにしてください。詳細は、Job APIを参照してください。
Python Processorノードを使って新しいプロセッサタイプを作成する方法 ¶
-
TOPネットワーク内で、
Python Processorノードを作成します。 -
このノードが上流のワークアイテムが完了するまで新しいワークアイテムを生成することができない(つまり、上流のワークアイテムからデータを読み込まないと、生成すべき新しいワークアイテムの数がわからない)ことがわかっているのであれば、 Generate When を“Each Upstream Item is Cooked”に設定してください。わからないのであれば、“Automatic”の設定のままにします。
-
Processor タブの Command フィールドは何もしません。このフィールドの目的は、ワークアイテムを生成するスクリプト内でそれをSpareパラメータとして参照することで、新しいワークアイテムのコマンドラインを設定できるようにするためにあります。ほとんどのユーザにとっては、スクリプト内でコマンドラインをハードコーディングするよりも、パラメータ内にコマンドラインをセットアップしてそれを参照した方が編集が楽だと思います。
-
ユーザ側でノードの挙動を制御できるようにするために、Spareパラメータを追加します。
このようにした方が、Pythonコードに値をハードコーディングするよりもまったく言って柔軟性があり便利です。 コードを書いている途中でインターフェースの改良を施したり、コードを書き終わった後でもパラメータを追加/除去が簡単にできます。
以下のSpareパラメータインターフェースを構築する方法のヘルプを参照してください。
-
Generateタブ内でコールバックスクリプトを記述します。 Generate タブのコールバックスクリプトは、このノードが生成するワークアイテムの内容、そのワークアイテムに設定するアトリビュート、ワークアイテム毎に走らせるコマンドラインを制御します。
以下のGenerateタブのヘルプを参照してください。 Generateコールバックのサンプルコードは、Generateのサンプルを参照してください。
Generateコールバックは、このノードが静的または動的のどちらなのかに応じてコールのされ方が異なります。
-
このノードが静的であれば、Generateコールバックは 1回だけ コールされます。 Generateコールバックは、入力ノード(s)がワークアイテムの生成を完了した後にのみ実行されるので、
upstream_itemsリストには、すべての上流のワークアイテムが入ります。 -
このノードが動的であれば、Generateコールバックは 複数回 コールされます。
upstream_itemsリストには、少なくとも1個のクック済みワークアイテムが入ります。 複数の上流のワークアイテムがほぼ同時に完了すると、PDGは、それらのワークアイテムをグループにして、そのワークアイテムのリストに対して生成ロジックをコールします。 最悪の場合、クックされた上流のワークアイテム毎に1回のGenerateコールバックがサイズ1の入力リストでコールされます。このノードが動的であるものの、上流のワークアイテムすべてが利用可能になるまで待機させたいのであれば、そのPython Processorノードの前に
 Wait for Allノードを配置してください。次に、そのPython Processorノードで以下のコードを使用することで、そのパーティション内の
Wait for Allノードを配置してください。次に、そのPython Processorノードで以下のコードを使用することで、そのパーティション内のWorkItemオブジェクトにアクセスすることができます:upstream_items[0].partitionItems
別の方法として、 Generate When パラメータを Each Upstream Item is Cooked から All Upstream Items are Cooked に変更するのも良いでしょう。
Note
必ず
parentキーワード引数を使って、このノードがどの上流のワークアイテムから生成した新しいワークアイテムなのかを指定してください。 これは、このノードが動的であっても必要です。 -
-
私たちは、コマンドラインにはPythonのワークスクリプトを走らせることを推奨しています。その理由は、実行ファイルを直接走らせるよりも柔軟性があって、ワークスクリプトはその結果をレポートすることができるからです。
以下のワークスクリプトの書き方のヘルプを参照してください。
既知の共有ネットワークファイルシステムの場所にワークスクリプトを配置すれば、コマンドラインからその共有場所を使用することができます。
または
Houdiniマシン上のどこかにワークスクリプトを配置して、このノードの Files タブのFile Dependencyとして、そのファイルパスを設定することができます。 これによって、そのファイルが各サーバーのディレクトリ上にコピーされるようになります。 次に、コマンドラインに
__PDG_SCRIPTDIR__を使用することで、その共有スクリプトディレクトリを参照することができます (別々のラッパースクリプトをコールする別々のタイプのワークアイテムを作成する場合は、それらのファイルパスを複数のFile Dependencyとして設定することができます)。 -
通常では、このノードの Regenerate Static タブでカスタムスクリプトを書く必要はありません。
デフォルトの実装では、何かのパラメータが変わるとワークアイテムをDirty(変更あり)にします。 通常では、これで十分なのですが、もっと賢いロジックを使いたい場合(例えば、URLの
etagをチェックして、それが変更されていれば、そのワークアイテムをDirtyにしたい場合)、このタブでそれを実装することができます。 -
Add Internal Dependencies タブは、このノードから生成されたいくつかのワークアイテムを、このノードから生成された他のワークアイテムに依存させたい場合にのみ、カスタムスクリプトを書く必要があります。
-
ユーザとネットワークの間で再利用できるようにプロセッサをアセットとしてパッケージ化したい場合、Python Processorノードからアセットを構築することができます。
インターフェースの構築 ¶
新しいプロセッサに処理させたい内容が決まっている場合、Spareパラメータを使ってユーザインターフェースをデザインすれば、それらのパラメータのオプションを参照するコードを記述することができます。
Tip
後でPython Processorノードをアセットに変換しても、Python Processorノードは自動的にそのSpareパラメータをアセットのインターフェースとして使用するようになります。
-
このノードに“Spare”パラメータを追加する方法は、Spareパラメータを追加する方法を参照してください。
スクリプトから簡単にパラメータが参照できるように、そのパラメータ名は短く、且つ、意味のわかる内部名を付けるようにしてください。
-
パラメータ値を使用することで、このノードによるワークアイテムの生成の挙動、ワークアイテムのアトリビュートの設定内容を変更することができます。以下を参照してください。
-
パラメータのデフォルト値を設定する時:
-
ローカスのパスをデフォルト値として使用しないでください。
__PDG_DIR__は任意のマシン上のPDG作業ディレクトリに展開されます。 -
ファイルパス内に
@pdg_nameを使用することで、ワークアイテム毎に固有なファイルパスを設定することができます。ワークアイテムの名前はHIPファイル内では固有です。つまり、出力されるファイルは、同じディレクトリ内に複数のHIPファイルがあって同時にそれらのHIPファイルをクックしない限りは、お互いに上書きし合うことはないはずです。
-
ワークアイテムの生成 ¶
Generate タブの onGenerate Callback エディタ内にコードを記述することで、ワークアイテムを生成することができます。 TOPネットワークは、このノードがワークアイテムを生成する必要が出た時に、このコードを走らせます。 例えば、TOPネットワークがクックを開始した時、または、ユーザが静的なワークアイテムを事前に生成するように要求した時です。
このコードは、以下で定義されたいくつかの便利な変数を使って、コンテキスト内で走ります:
名前 |
タイプ |
説明 |
|---|---|---|
|
現行PDGグラフノードの参照(これは、Houdiniネットワークノードのことでは ありません )。 Python Processorノード/アセットのSpareパラメータは、このオブジェクト内にpdg.Portオブジェクトとしてコピーされます。
|
|
|
このノードのワークアイテムホルダーオブジェクトの参照。 このオブジェクトのメソッドを使って、新しいワークアイテムを生成することができます。 |
|
|
|
入力のpdg.WorkItemオブジェクトのリスト。入力のワークアイテムが何も存在しなければ、空っぽのリストです。 あなたのノードがワークアイテムを生成するノードである場合、このリストを使って、入力のワークアイテムから新しいワークアイテムを生成することができます。 |
|
どのような方法でこのノードにワークアイテムを生成させたいのかに応じて、ここには このノードが動的にワークアイテムを生成する際に、これを使って特定の事前条件をチェックするように、スクリプトを作り込むことがことができます。 ほとんどのユーザにとっては、この変数の値は無視しても構いません。 |
以下には、Pythonコードでよく使うタスクを達成させる方法について載せています:
| To... | Do this |
|---|---|
|
Generateコールバックから新しいワークアイテムを生成する |
|
|
新しく生成されたワークアイテムに対してアトリビュートを設定する |
ワークアイテムの new_item = item_holder.addWorkItem(index=0) new_item.setStringAttrib("url", "http://...") |
|
Spareパラメータの値を読み込む |
このノードは、どのSpareパラメータの値も
重要: ワークスクリプトから(通常では)パラメータポートにアクセスする方法が ない ので、そのパラメータからワークの挙動に影響を与えたいのであれば、評価されたパラメータ値をワークアイテムのアトリビュートにコピーしなければなりません: new_item = item_holder.addWorkItem(index=0) # この新しいワークアイテムのコンテキストでURLパラメータを評価します。 url = self["url"].evaluateString(new_item) # ワークアイテムで評価された値をアトリビュートに格納します。 new_item.setStringAttrib("url", url) 一般的には、パラメータはワークアイテムが生成された 後に 、その新しいワークアイテムをそのパラメータが評価されるコンテキストとして使って、そのパラメータを評価するべきです。
そうすることで、ユーザが もちろん、ワークアイテムのコンテキストを使わずに評価しなければならないパラメータも存在します。例えば、生成したいワークアイテムの数を指定するパラメータがそれです。 |
|
走らせたいコマンドラインを指定する |
new_item = item_holder.addWorkItem(index=0) new_item.setCommand("__PDG_PYTHON__ /nfs/scripts/url_downloader.py") ここでコマンドラインをハードコーディングしなくても、このノードの Command パラメータを参照することができます: command_line = self["pdg_command"].evaluateString() new_item.setCommand(command_line)
Tip ワークスクリプトを指定した場合、コマンドラインに対してワークアイテムの情報を渡す必要はなくて、Python便利関数を使用することで、そのワークスクリプトからその情報を照会することができます(ワークスクリプトの書き方を参照してください)。 ワークスクリプトに他のタイプの情報/オプションを渡したいのであれば、単純なメソッド(位置指定引数や |
|
ユーザに警告またはエラーを発信する |
import pdg # 入力のワークアイテム毎に生成される新しいワークアイテムの数を取得します。 per_item = self["peritem"].evaluateInt() if per_item > 16: # Too many! raise pdg.CookError( "Can't create more than 16 items per incoming item" ) # 新しいワークアイテムの生成を継続します... |
Generateスクリプトのサンプル ¶
例えば、curlユーティリティプログラムを使って、URLsからファイルをダウンロードするプロセッサを構築したいとします。
上流のワークアイテムが存在すれば、それらのワークアイテムから新しいワークアイテムを生成し、存在しなければ“ゼロから”1個の新しいワークアイテムを生成して、このノードのパラメータからアトリビュートを設定したいです。
Spareパラメータを追加 ¶
URLからファイルをダウンロードするノードを構築するために、2個のSpareパラメータを追加します:1個目はダウンロード元のURLを設定するパラメータ、2個目はダウンロード先のファイルパスを設定するパラメータです。
内部名 |
ラベル |
パラメータタイプ |
|---|---|---|
|
URL |
String |
|
Output File |
String |
ユーザがこれらのフィールドに@attributeエクスプレッションを使用することで、現行ワークアイテムのアトリビュートに基づいてパラメータ値を変更できることを忘れないでください。
Generateスクリプト ¶
Generate タブの onGenerate Callback エディタに以下のコードを入力します:
# パラメータを評価して、その値をワークアイテムのアトリビュートにコピーする便利関数を定義します。 def set_attrs(self, work_item): # このワークアイテムのコンテキスト内でパラメータポートを評価します。 url = self["url"].evaluateString(work_item) # ダウンロード先のURLを取得します。 outputfile = self["outputfile"].evaluateString(work_item) # 新しいワークアイテムにアトリビュートを設定します。 work_item.setStringAttrib("url", url) work_item.setStringAttrib("outputfile", outputfile) # このワークアイテムが走らせるコマンドラインを設定します。 work_item.setCommand('__PDG_PYTHON__ __PDG_SCRIPTDIR__/url_downloader.py') if upstream_items: # 上流のワークアイテムが存在すれば、それらのワークアイテムから新しいワークアイテムを生成します。 for upstream_item in upstream_items: # 上流のワークアイテムに基づいて、新しいワークアイテムを生成します。 new_item = item_holder.addWorkItem(index=upstream_item.index, parent=upstream_item) # パラメータに基づいて、その新しいワークアイテムのアトリビュートを設定します。 set_attrs(self, new_item) else: # 上流のワークアイテムが存在しなければ、1個の新しいワークアイテムを生成します。 new_item = item_holder.addWorkItem(index=0) # パラメータに基づいて、その新しいワークアイテムのアトリビュートを設定します。 set_attrs(self, new_item)
Generateスクリプトのテスト ¶
上記のGenerateスクリプトをPython Processorノードに記述し、そのノードのOutputフラグを有効にして、 Tasks ▸ Generate Static Work Items を選択すれば、そのスクリプトをテストすることができます。 入力なしでテストしたり、入力を接続してその上流のワークアイテムに対してテストしてみてください。 Task Graph Tableを開けば、生成されたワークアイテムのアトリビュートを確認することができます。
ワークスクリプトを記述する ¶
ワークアイテムのコマンドラインで参照したurl_downloader.pyスクリプトをこれから実装していく必要があります。
詳細は、以下のワークスクリプトの書き方を参照してください。
ワークスクリプトの書き方 ¶
ワークアイテムを実際にローカルマシンまたはレンダーファームに対してスケジュールを組んでから、そのワークアイテムが走らせると、そのワークアイテムはコマンドラインを実行します。 このコマンドラインには、単純に実行ファイルを走らせるコマンドラインを指定することができますが、もっと柔軟且つ便利に使えるようにするために、私たちは、そのコマンドラインにはPythonの ワークスクリプト を走らせることを推奨しています。 このワークスクリプトは、ワークアイテムのアトリビュートにアクセスして、その実行方法を制御したり、そのワークスクリプトから生成されたファイルに基づいてワークアイテム上に出力アトリビュートを設定することができます。
Python Scriptノードの場合、このワークスクリプトを __Script__フィールド内でタイプし、そのノードが生成したワークアイテムに対してそのスクリプトが実行されるように自動的に設定されます。 Python Processorノードの場合、このスクリプトを外部(レンダーファームと共有されているネットワークファイルシステム内)で作成し、あなたが作成したワークアイテムがそのスクリプトを実行するように設定する必要があります。
Python Scriptノードと外部スクリプトファイルの違い ¶
-
Python Scriptノードでは、
work_item変数には、自動的に現行ワークアイテムを表現したpdg.WorkItemオブジェクトが格納されます。Evaluate In Process を有効にすると、
self変数は現行グラフノードを表現したpdg.Nodeオブジェクト、parent_item変数は現行ワークアイテムの派生元の親ワークアイテムを表現したpdg.WorkItemオブジェクトです。 -
外部ラッパースクリプトでは、以下のヘッダーコードを使用することで、現行ワークアイテムを表現したpdg.WorkItemオブジェクトを取得することができます:
import os from pdgjson import WorkItem # 現行ワークアイテムの名前は、環境変数で利用可能で、 # ワークアイテムのプロセス外の表現を構築する時に自動的に使用されます。 work_item = WorkItem.fromJobEnvironment()
Note
Python Processorノードをデジタルアセットとして保存した場合、
pdgcmd.pyとpdgjson.pyが自動的にFile Dependencyとして追加されます。 Python Processorノードをそのままで使用したい場合、pdgcmd.pyとpdgjson.pyをFile Dependencyとして手動で追加する必要があります。これらのスクリプトは以下の場所にあります:-
$HHP/pdgjob/pdgcmd.py -
$HHP/pdgjob/pdgjson.py
ワークアイテムの作業ディレクトリのスクリプトフォルダにpdgcmdモジュールがコピーされるので、ワークスクリプトを Evaluate In Process として実行した場合は
from pdgjob import pdgcmdを使用することができ、そうでない場合はimport pdgcmdを使用することができます。 -
-
Python Scriptノードでは、ワークアイテムオブジェクトとアトリビュートの親をimportすることなくそれらを自動的に利用可能です。外部ワークスクリプトでは、
pdgjsonモジュールからそれらをimportして、ジョブ環境からワークアイテムをインスタンス化する必要があります。プロセス外のワークアイテムは、通常のワークアイテムのPython APIのサブセットを持っています。そのサブセットだけを使って、アトリビュートにアクセスしたり修正したり、出力ファイルを追加することができます。# Python Scriptノードでは、このimportは不要です。 # 外部ジョブスクリプトでのみ以下のimportが必要です。 from pdgjson import WorkItem work_item = WorkItem.fromJobEnvironment() # 以下のコードは、In-ProcessとOut-Of-Processの両方で動作します。 # Out-Of-Processを実行すると、このwork_itemは標準のpdg.WorkItem APIの軽量の実装になり、 # 基本的なアトリビュートと出力ファイルアクセスに対応しています。 url = work_item.stringAttribValue("url") # 出力ファイルをwork_itemに追加します。 work_item.addOutputFile("myfile.txt", "file/text")
-
通常のアトリビュートAPIを使って、外部スクリプトファイルからワークアイテム上にアトリビュート値を設定することができます。 この変更は、PDGに自動的に伝搬し、グラフ内のワークアイテムに適用されます:
from pdgjson import WorkItem work_item = WorkItem.fromJobEnvironment() work_item.setIntAttrib("outputsize", 100)
-
PDG_PYATTRIB_LOADER環境変数で指定されたPythonモジュールを使用するか、または、その環境変数を設定しないのであればビルトインのrepr関数を使用して、Pythonオブジェクトアトリビュートをシリアライズします。ホストのHoudiniプロセスは、同じモジュールを使用してそのPythonオブジェクトアトリビュートをアンシリアライズします:from pdgjson import WorkItem work_item = WorkItem.fromJobEnvironment() custom_data = {'key': [1,2,3], 'second_key': (4,5)} work_item.setPyObjectAttrib("custom_data", custom_data)
-
外部ワークスクリプトでは、時折、ワークアイテムからの追加で型が決まっていない情報をスクリプト側にコマンドラインオプションとして渡した方が簡単な場合があります。その場合は、ワークスクリプト側でそのコマンドラインのオプションを復元します。
ワークを実行する ¶
-
ワークスクリプトでは、Pythonですべてのワークを処理しても構いませんし、または、外部の実行ファイルをコールするだけの“ラッパー”として使用しても構いません。
例えば、URLからファイルをダウンロードするには、ビルトインのPythonライブラリを使用したり、外部の
curlユーティリティをコールすることができます。import requests from pdgjob import pdgcmd # システムのPythonでプロセスが不足すると、pdgcmdをHFSからではなくPDGの作業ディレクトリから直接インポートする必要があります。 # # import pdgcmd url = work_item.stringAttribValue("url") outfile = work_item.stringAttribValue("outputfile") local_outfile = pdgcmd.localizePath(outfile) r = requests.get(url, allow_redirects=True) open(outfile, "wb").write(r.content)
または
import subprocess from pdgjob import pdgcmd # システムのPythonでプロセスが不足すると、pdgcmdをHFSからではなくPDGの作業ディレクトリから直接インポートする必要があります。 # # import pdgcmd url = work_item.stringAttribValue("url") outfile = work_item.stringAttribValue("outputfile") local_outfile = pdgcmd.localizePath(outfile) rc = subprocess.check_call( ["curl", "--output", outfile, "--location", url] )
-
ワークアイテムからファイルパスを取得したい場合、
pdgcmd.localizePath()を使用することで、プレースホルダーと環境変数を展開して、このマシンに特化したパスを作ることができます。 -
スクリプトで中間結果ファイルを生成して、それを一時ディレクトリに配置したい場合、
os.environ["PDG_TEMP"]を使用することで、その一時ディレクトリのパスにアクセスすることができます。 -
スクリプト/実行ファイルがゼロ以外の戻りコードで終了した場合、そのワークアイテムがエラーとしてマークされます。
stdoutまたはstderrへの出力が、そのワークアイテム上に取り込まれます。 -
ワークスクリプトから外部プログラムを実行するには、Pythonのsubprocessモジュールの以下の関数を使用します。これらの関数は、Python標準ライブラリの古くて機能が低い安全でないいくつかの関数を置換します。
subprocess.call()コマンドラインを実行して、その戻りコードを返します。
subprocess.check_call()コマンドラインを実行して、そのコマンドが失敗すると例外を引き起こします(ゼロ以外の戻りコード)。
subprocess.check_output()コマンドラインを実行して、その出力をバイト文字列で返します。そのコマンドが失敗すると例外を引き起こします(ゼロ以外の戻りコード)。
-
check_系の関数を使用すると、あなたのスクリプトが自動的にゼロ以外の戻りコードで終了するようになり、例外トレースバックの一部としてOSエラーをプリントします(例えば、No such file or directory)。もっとコントロールが必要であれば、その例外をキャッチして、あなた独自のエラーメッセージをstderrにプリントすることができます。 -
これらの関数は、フルコマンドラインの文字列を1番目の引数として受け取ることができますが、安全性と堅牢性の観点で最も良い方法は、コマンド、オプション、ファイルパスを別々の文字列のリストとして渡すことです:
import subprocess rc = subprocess.call(["curl", "--config", configfile, "--output", outfile, url])
別々に文字列を使用することで、エラーがキャッチしやすくなり、特定のタイプの暴走を回避することができます。 他にも、ファイル名に特殊文字(例えば、スペース)のエスケープを気にする必要がないことがメリットです。
-
これらの関数に引数を与えることで、開いたファイルの内容をコマンドの
stdinにパイプさせたり、コマンドのstdoutを開いたファイルにパイプさせることができます。コマンドをシェル内で走らせなければならない場合には、shell=Trueを指定することができます。
-
Job API - 結果をレポートする ¶
Job APIを使用することで、PDGで実行されているワークアイテムに出力ファイルとアトリビュートをレポートすることができます。
環境変数 ¶
システムは、いくつかの便利な環境変数が設定された環境内でワークアイテムのコマンドラインを実行します。
-
TOPスケジューラによって実行された外部スクリプトでは、指定した言語のいつもの方法で環境変数にアクセスすることができます。例えば、Pythonなら
os.environ["PDG_DIR"]、シェルなら$PDG_DIRを使用します。
PDG_RESULT_SERVER
結果の送信先となるサーバーのIPアドレスとポート番号を含んだ文字列。
通常では、これを手動で検索する必要はなくて、例えばpdgcmd.addOutputFile(file_path)をコールするだけで、自動的にその環境からこの値を取得することができます。
PDG_ITEM_NAME
現行ワークアイテムの名前。この変数をpdgjson便利関数で使用することで、その名前からそのワークアイテムのデータを照会して、そのデータからWorkItemオブジェクトを構築することができます。
import os # 現行ワークアイテムの名前は、環境変数から参照することができます。 item_name = os.environ["PDG_ITEM_NAME"] # この名前を使ってワークアイテムのデータを照会し、そのデータからWorkItemオブジェクトを構築します。 work_item = WorkItem.fromFile(getWorkItemJsonPath(item_name)) # これは、WorkItem.fromJobEnvironment関数を使用することと同じです: same_item = WorkItem.fromJobEnvironment()
PDG_INDEX
現行ワークアイテムのインデックス。
PDG_DIR
Scheduler系ノードで指定したTOPネットワークの作業ディレクトリ。
PDG_TEMP
その作業ディレクトリ内の現行セッション用共有一時ファイルディレクトリ。
デフォルトは$PDG_DIR/pdgtemp/‹houdini_process_id›です。
PDG_SCRIPTDIR
その一時ファイルディレクトリ内の共有スクリプトディレクトリ。
スクリプトファイルがファイルディペンデンシーとして登録されていれば、それらのスクリプトファイルがこのディレクトリ内にコピーされます。
デフォルトは$PDG_TEMP/scriptsです。
他にも、単に共有ネットワークファイルシステム内の特定の場所にスクリプトを配置しても構いません。
Python Processorノードからアセットを生成する ¶
あなたの期待通りにPython Processorノードが動くようになったのであれば、後はそのノードをアセットに変換してしまえば、そのノードが簡単に再利用できるようになります。
-
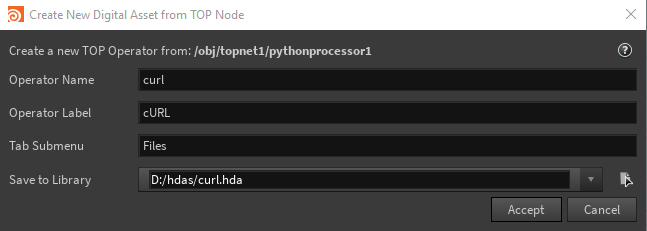
Python Processorノードを選択します。パラメータエディタで、 Save to Digital Asset をクリックします。
-
表示されたダイアログに必要事項を記入して Accept をクリックします。
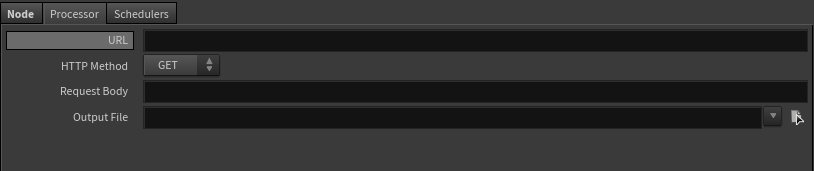
この新しいアセットタイプは、Python Processorノード上のSpareパラメータを自動的に Processor タブのパラメータインターフェースとして使用するようになります。
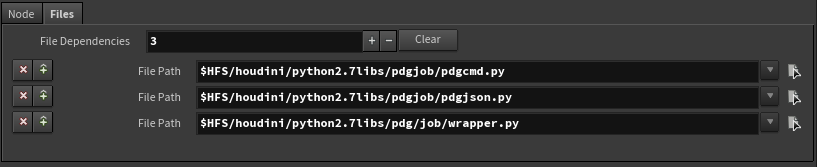
ファイルディペンデンシーには、対応モジュールが自動的に追加されます。
-
この新しいアセットのパラメータインターフェースを続けて編集することができます。しかし、以下の点には注意してください:
-
パラメータインターフェースを編集した際にHoudiniがSpareパラメータの処理をどうするのか尋ねてきた場合、 Destroy All Spare Parameters をクリックしてください。
-
ワークアイテムのコマンドラインを設定するための Command パラメータを参照しないのであれば、混乱を避けるために、パラメータインターフェースからそのパラメータを非表示または削除してください。
-