| On this page |
Overview ¶
PDG stands for procedural dependency graph which is a procedural architecture that defines tasks and their dependencies to structure, schedule, and distribute work. You can use it to support automated and repeatable content pipelines in film, telvision, and real-time productions.
PDG helps to solve limitations of more traditional and linear workflows. In these workflows, large tasks often run one after another even when some parts could run at the same time. PDG breaks the work into smaller, more manageable tasks and allows you to control how each task depends on the others. This makes it easier to use multiple CPU cores more efficiently and run tasks at the same time when possible. It also lets you update only the tasks that changed instead of redoing the entire workflow. Computing resources include local CPU cores, render farms, or cloud-based systems.
TOPs stands for Task Operators, it helps to integrate PDG inside Houdini and provides dependency relationships through a node based network. A TOP network uses nodes that generate and organized work items, define dependencies, and pass data through attributes. TOPs is the network that helps orchestrate tasks that may involve geometry, simulation, rendering, machine learning, or external tools.
Traditional workflows vs. PDG workflows ¶
Although both workflows produce the same final output, PDG breaks the work into granular tasks and manages dependencies procedurally which allows for things to run in parallel and improves scalability.
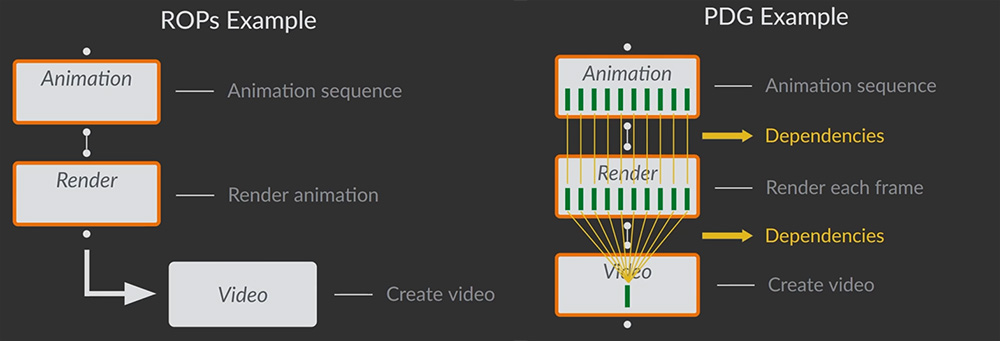
ROP based workflow
This example shows how a traditional ROP network handles a simple animation to render then a video pipeline versus the same pipeline in PDG. A ROP network processes work as a linear sequence. This means each stage must finish entirely before the next stage begins.
-
Generate the animation.
-
The network generates the full animation sequence (ex. frame 1-10).
-
This step must complete before rendering can start.
-
-
Render the animation.
-
The renderer outputs each frame of the animation.
-
Rendering does not begin until all animation output is ready.
-
-
Create the final video.
-
Once every frame is rendered, a final tool such as FFmpeg ROP converts the image sequence into a video file.
-
This results in downstream nodes not able to begin processing until all upstream nodes have full completed. This limits the scalability and doesn’t allow you to take full advantage of available parallelism on a local machine or render farm.
PDG worfklow
In PDG, the same workflow is broken down into individual tasks known as work items with dependencies between them. This allows the tasks to process in parallel and only wait on tasks that you set.
-
Animation task generation.
-
PDG creates one work item per animation frame. For example, a 10 frame animation creates 10 “animation” tasks.
-
Each task cooks independently.
-
-
Render task generation.
-
For each animation frame, PDG generates a corresponding “Render frame” task.
-
Each render tasks depends only on its matching animation. For example, render frame 6 waits only for animation frame 6.
-
When a single animation frame is complete, its render task can begin immediately.
-
-
Video creation task.
-
PDG creates a final “Create video” task.
-
This task depends on all render tasks which ensures the full image sequence is available before stitching.
-
The PDG workflow allows for individual tasks to begin executing as soon as their prerequisites have finished. You can also set depedency structures that define which tasks rely on which piece of data.
Working with TOPs ¶
You can specify work to be done and how to manipulate the results of that work by building a network of ![]() TOP nodes. TOP nodes generate work items to do work and/or store information in attributes. There are several types of TOP nodes, but the two main types are: processors that generate new work items and partitions that create dependencies between items so they wait until all items in the partition finish.
TOP nodes. TOP nodes generate work items to do work and/or store information in attributes. There are several types of TOP nodes, but the two main types are: processors that generate new work items and partitions that create dependencies between items so they wait until all items in the partition finish.
A TOP network describes a recipe for generating work items, efficiently running them in processes on a single machine or render farm, and figuring out dependencies so as many items can run in parallel as possible. This recipe is a PDG (Procedural Dependency Graph) that describes the work items to be completed and their dependencies.


By establishing the network of dependencies between all the bits of work needed to produce the final output, TOPs can find the more efficient way to “cook” the city recipe. It can also do the minimum amount of work necessary to “recook” the city when something changes, because it knows which parts depend on the changed information.
As part of Houdini, TOPs are especially geared toward accomplishing effects work, such as simulation, rendering, and compositing, however it can be useful for any kind of work that can be broken up into individual items with dependencies between them.
TOP node UI ¶

For more information, see TOP network user interface.
Processors ¶
Processors generate new work items. Processors can generate multiple new work items based on previous work items (“fan-out”).
A processor node can create new work items from scratch, based on the node’s parameters, or it can generate new work items from the work items incoming from the input node. Many nodes can work both ways. If the ![]() Wedge node has no input, it will create work items for the number of wedges specified in its parameters. If it has an input, it create new work items for the number of wedges, multiplied by the number of incoming work items.
Wedge node has no input, it will create work items for the number of wedges specified in its parameters. If it has an input, it create new work items for the number of wedges, multiplied by the number of incoming work items.
When a processor node generates a new “child” work item based on a “parent” item, it passes down the parent’s attributes, so work items can pass results downstream.
Partitions ¶
Partition nodes join together incoming work items together based on various criteria. This is how PDG combines multiple pieces of work into a single piece for further processing (“fan-in”).
Different partition nodes group together upstream work items in different ways.
Partitioning has two effects
-
It creates dependencies between the grouped work items, so the partition doesn’t continue processing until all the work items in the group are done.
-
It (optionally) merges the attribute values on the grouped work items. So, for example, any work items created from the partition will receive the aggregated list of
outputfile paths from the grouped work items as theirinputattribute.
The most commonly used partition node is ![]() Wait for All, which groups all incoming work items into a single partition, causing the partition to wait for all the upstream work to finish before moving on.
Wait for All, which groups all incoming work items into a single partition, causing the partition to wait for all the upstream work to finish before moving on.
You can partition based on attributes (for example, grouping all items that worked on the same frame), by a custom function, or spatially. For example, if you scattered trees over a terrain, you could divide a terrain into a grid and group all the items generating geometry in a certain tile together.
By themselves, the items inside partition nodes don’t do any work. They just hold the merged information of the grouped work items. Subsequent work items can then operate on the merged information.
Schedulers ¶
Scheduler nodes run executables inside work items. To do the work you specified when the network runs, something must take the commands that are ready to go, create an execution environment, and run them.
-
Different scheduler types represent different methods for running the executables. For example, the Local Scheduler runs executables using a process pool on the local machine, while the HQueue Scheduler puts the executables on an HQueue render farm.
-
You can have multiple scheduler nodes in a TOP network, allowing you to set up the network to cook in different ways depending on circumstances (for example, you might want to cook locally while testing changes and only cook on the farm as part of a nightly process). The TOP Network node’s Default TOP Scheduler parameter controls which scheduler is used to cook the network.
Simplified TOP network example ¶
The simplified illustration on the right depicts a basic network to render out five frames of an animation at different quality levels, and create mosaics of the same frame at different qualities, so we can understand how the quality setting affects the final image.

-
A
 Wedge node generates four “dummy” work items containing wedge variants (for example, different values for Mantra’s Pixel Samples parameter).
Wedge node generates four “dummy” work items containing wedge variants (for example, different values for Mantra’s Pixel Samples parameter). -
Append a
 ROP Mantra Render node and set the frame range to 1-5. This generates 5 new work items for each “parent” item. The wedged attribute is passed down to the new work items.
ROP Mantra Render node and set the frame range to 1-5. This generates 5 new work items for each “parent” item. The wedged attribute is passed down to the new work items. -
A
 Partition by Frame node creates new “partition” items with dependencies on the work items with the same frame number. This makes the partition wait until all variants of the same frame are done before proceeding to the next step.
Partition by Frame node creates new “partition” items with dependencies on the work items with the same frame number. This makes the partition wait until all variants of the same frame are done before proceeding to the next step. -
An
 ImageMagick node generates new work items to take the rendered variants of each frame and merge them together into a mosaic image.
ImageMagick node generates new work items to take the rendered variants of each frame and merge them together into a mosaic image.Of course, we could do more like
 overlay text on the image showing what settings correspond to each sub-image in the mosaic.
overlay text on the image showing what settings correspond to each sub-image in the mosaic. -
A
 Wait for All node at the end generates a partition item that waits for all work to finish.
Wait for All node at the end generates a partition item that waits for all work to finish.This lets you add work items after the “wait for all” that only run after all the “main” work is done. This is where you would put, for example, post-render scripts and/or notifications to the user that the work is done.
See commonly used TOP nodes for more information.
Work items ¶
Each processor node in the TOP network generates a certain number of work items. The work items created by a node a depicted inside the node body in the network editor (see network interface below for more information).
Many work items represent a “job”, that is, a script or executable to run, either in a process on a single computer or on a render farm. However, some work items exist simply to hold attributes, and don’t actually cause any work to be done.
For example, work items created by the ![]() HDA Processor node represent work: they cook a Houdini asset on an input file. However, items created by the
HDA Processor node represent work: they cook a Houdini asset on an input file. However, items created by the ![]() File Pattern node are just holders for each matched file path. Work items in downstream processors are expected to do something with those file names.
File Pattern node are just holders for each matched file path. Work items in downstream processors are expected to do something with those file names.
Attributes ¶
A work item contains attributes, named bits of information similar to attributes on a point in Houdini geometry. The script or executable associated with the work item can read the attributes to control the work they do. Attributes are passed down to work items created from “parent” work items, so you can use them to have the result of a work item affect the processing of its child items, group items together, and pass information down through the network.
Custom code can read attributes to control generation of work items, however the most common use of attributes is to reference them in parameters of TOP nodes and/or Houdini networks and nodes that are referenced by the TOP network.
-
For example, let’s say you want to wedge different render qualities. You can use the
Wedge TOP to create work items that have a pixelsamplesattribute set to different values. Then, in theROP Mantra Render TOP, you can set Pixel samples using @pixelsamplesto reference the attribute value. -
You can also reference work item attributes in external assets/networks called by the TOP network. For example, the
 HDA Processor cooks a Houdini asset for each work item. You can use
HDA Processor cooks a Houdini asset for each work item. You can use @attributereferences in that asset’s parameters to pull values from the work item.
You can reference a component of a vector using @attribute.‹component›, where ‹component› is a zero-based number, or x, y, or z (equivalent of 0, 1, 2). For example @pos.x or @pdg_output.0. You can reference all components of an attribute array as a space-separated string using pdgattribvals.
Nodes and ![]() custom code can add arbitrary attributes, however work items also have a few built-in attributes that are always accessible.
custom code can add arbitrary attributes, however work items also have a few built-in attributes that are always accessible.
For more information about attributes, see Using Attributes.
In-process vs. out-of-process ¶
Work items cook in either the current Houdini session (in-process) or in a separate process that gets created by a Scheduler node (out-of-process). This includes work items that cook on the farm like the ![]()
![]() HQueue Scheduler TOP and
HQueue Scheduler TOP and ![]()
![]() Tractor Scheduler TOP nodes which run out-of-process.
Tractor Scheduler TOP nodes which run out-of-process.
Work items that cook in-process have access to all of the data in the current Houdini session, but it is not possible for them to edit the scene in any way or cook other network contexts because they are being processed in the background. Work items that cook out-of-process however have some start up overhead and have access to only a limited about of information (just the saved work item attribute data).
Static vs. dynamic ¶
Important Note
The static vs. dynamic terminology has mostly been replaced by the Generate When parameter (found on all the Processor nodes) terminology. This parameter configures when a node runs its internal logic to produce work items. For example, generate work items when All Upstream Items are Generated, All Upstream Items are Cooked, or when Each Upstream Item is Cooked. The parameter’s default option is Automatic, which tries do the correct thing for a node based on what PDG can understand about its graph.
Static
Some work items are known to be needed before the TOP network even starts running, just based on the node parameters. These are called static work items.
For example, a ![]() ROP Mantra TOP with no inputs generates a work item for each frame to render, and the number of frames to render is set in the parameters, so the number of work items is known ahead of time. And if the next node just generates a new work item for each incoming work item, then its work items are known “statically” as well.
ROP Mantra TOP with no inputs generates a work item for each frame to render, and the number of frames to render is set in the parameters, so the number of work items is known ahead of time. And if the next node just generates a new work item for each incoming work item, then its work items are known “statically” as well.
Film workflows are often frame-based and so lend themselves to generating static work items, because the number of frames to render is known ahead of time.
Dynamic
Sometimes work items can only be generated once the work is being done. These are called dynamic work items.
Games and effects workflows are often more dynamic. For example, a secondary simulation on top of crowd agents might divide up the crowd into tiles based on how many agents are in each tile. This can only be done dynamically after generating the crowd simulation and reading in the files.
-
As a general rule of thumb, static is preferable to dynamic: because the number of work items is visible, you can get a sense of how much work will be done, and Houdini can give more accurate estimates of percent completed.
-
However, depending on the workflows, dynamic work items can be unavoidable, and in fact almost the entire network may be dynamic. For example, in a games workflow where you generate a level from layout curves, you don’t know how much work there is to do until you intersect the curves with other curves, intersect the curves with tiles, and so on.
-
There might be cases where Houdini can’t tell whether work is static, and gives you the choice between generating work items dynamically or statically. In these cases, it’s always safe to mark the work dynamic, since the TOP network can always figure out what work items are needed at runtime. However, if you know that the work items are static, you can mark the node as static to get the advantages of static items.
(A Wait for All node node can convert a dynamic number of work items to a static number (one). Other partitions may also convert dynamic to static. These cases should be handled by the Automatic setting, without you needing to change node settings manually.)
-
Most processor nodes have a Generate When menu that lets you choose Static, Dynamic, or Automatic (Automatic means “if this node is capable of static generation, or it has no inputs, generate static”). Processors will lack this option if they can only work dynamically or only work statically.
-
Some partition nodes have a parameter called Use dynamic partitioning. Turn this on when the partitioning depends on information generated dynamically. Turn it off if the partitioning only depends on information that was already “known” in the closest upstream static work items, in which case the groupings can also be computed statically. (Some partition nodes may not provide this option if how the node works dictates dynamic or static partitioning.)
-
Tip
If you have a TOP network that has no cached results (no work items inside the nodes), you can choose Tasks ▸ Generate Static Work Items in the network editor to generate all statically-known items. This can often help give a sense of how much work is involved in the network.