| On this page |
Overview ¶
To actually do the work you specified when the network runs, something must take the commands that are ready to go, create an execution environment, and run them. In a TOP network, this is the scheduler node.
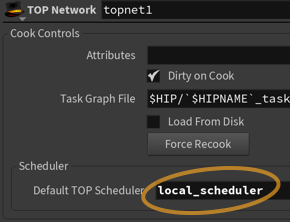
You can have more than one scheduler in a TOP network, however the scheduler that cooks the network is specified on the TOP network node.
Having multiple schedulers allows you to set up different “profiles” and switch between them (for example, a local scheduler for small-scale testing, and a render farm scheduler for full production runs).
You can override the scheduler used for certain nodes. This lets you run small jobs and filesystem modifications locally, instead of incurring the overhead of sending them out to a farm. (Some nodes even have an option to do work in the main process, rather than scheduling them at all.) A node can also override certain top-level job parameters.
Tip
You can switch the default scheduler by selecting Set As Default Scheduler on the RMB menu of a Scheduler Node.
The ![]() default scheduler node for new TOP networks schedules work using a process queue. Depending on the workload, this may actually be faster than using a render farm because of the lower overhead.
default scheduler node for new TOP networks schedules work using a process queue. Depending on the workload, this may actually be faster than using a render farm because of the lower overhead.
Out of the box, TOPs has built-in scheduler nodes for several render farm packages (see below).
TOPs only works with distributed setups where the controlling machine and all servers share a network filesystem.
Scheduler types ¶
|
The default scheduler: schedules work using a process queue on the local machine. |
|
|
This is Houdini’s free management software, suitable for small render farms. See |
|
|
Compute management toolkit by Thinkbox software. |
|
|
Render management software by Pixar. |
|
|
Controls the scheduling of in-process work items, which run asynchronously in the Houdini process. |
|
|
Render management software by Binary Alchemy. |
Custom schedulers ¶
You can use custom scheduler bindings to integrate other third party or in-house scheduling software.
Scheduler Override ¶
| To... | Do this |
|---|---|
|
To override the scheduler used for a single node |
To revert a node to using the default scheduler specified on the network node, set the node’s TOP scheduler path field to be blank. |
Scheduler Job Parms / Properties ¶
| To... | Do this |
|---|---|
|
Override job execution parameters for a single node |
Schedulers can have individual parameters for how they schedule and execute commands. You can override some of these settings per-node. TOPs uses the properties system to override scheduler settings. For example you may wish to set some environment variables for work items in a particular node.
|
|
Automatically add Job Parms to TOP nodes |
Sometimes your pipeline requires that certain Job Parms be always added for certain nodes. For example since the n = kwargs['node'] templ = hou.properties.parmTemplate('top', 'hqueue_resources') parmtuple = n.addSpareParmTuple(templ, ('Schedulers','HQueue'), False) parmtuple.set(['sidefx.license.render']) You could even set the parm value to an hscript expression that uses work item attributes to determine the correct value at cook-time. For example if the license type is held by the work item string attribute # ... parmtuple.set(['`@renderlicense`']) |
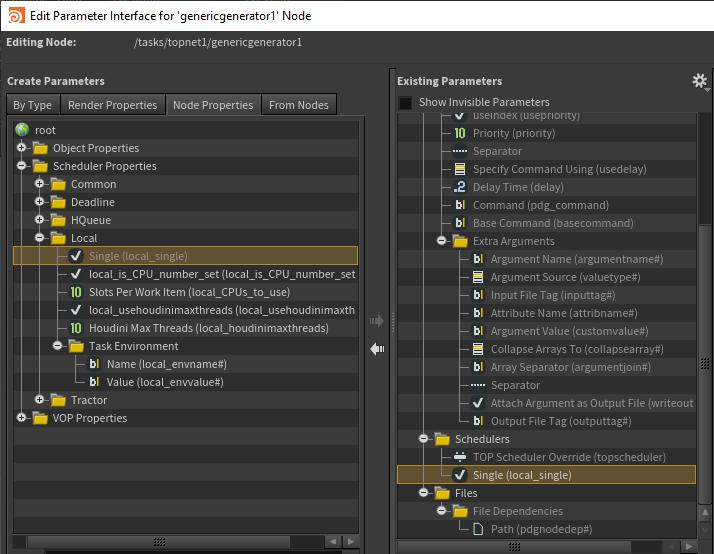
Local scheduler resource limits ¶
You can change the limit on the number of compute resources available to the Local Scheduler node (the default limit is the number of cores in the local computer).
-
Both HQueue and the Local Scheduler have a concept of how many “CPUs / slots” (an abstract unit) a job requires, and a maximum number of slots on a machine to use to run jobs simultaneously.
-
For example, if a certain job is itself multi-processing or multi-threaded, using four cores, you can mark that job as requiring 4 slots. The Local Scheduler or HQueue Scheduler will then only schedule the job if the machine has at least 4 “free” slots below the maximum limit.
-
To specify the number of slots the jobs generated by a TOP node require:
-
Select the TOP node.
-
In the parameter editor, click the Schedulers tab.
-
Press the Add Job Parms button. This will pop open a menu of all registered Schedulers.
-
Select the Local Scheduler item.
-
In the Scheduler Properties tree folder are all the overridable properties for each type of scheduler. Select Slots Per Work Item below the Local folder.
-
Press the
 button. This will install those properties onto the TOP node.
button. This will install those properties onto the TOP node. -
Dismiss the window, then toggle on Slots Per Work Item and set the number of slots to assign.
Note
You can create an expression on this parameter if you want to vary it’s value based on work item attributes.
-
-
The
 Local Scheduler’s Total Slots lets you specify the maximum number of slots the TOPs is allowed to use simultaneously while cooking.
Local Scheduler’s Total Slots lets you specify the maximum number of slots the TOPs is allowed to use simultaneously while cooking. -
Similarly,
 HQueue CPUs per Job lets you specify how many 'CPU' slots a job occupies.
HQueue CPUs per Job lets you specify how many 'CPU' slots a job occupies.
(Future versions may allow limits on other resource types, such as databases, similar to HQueue.)
Scheduling system visually ¶
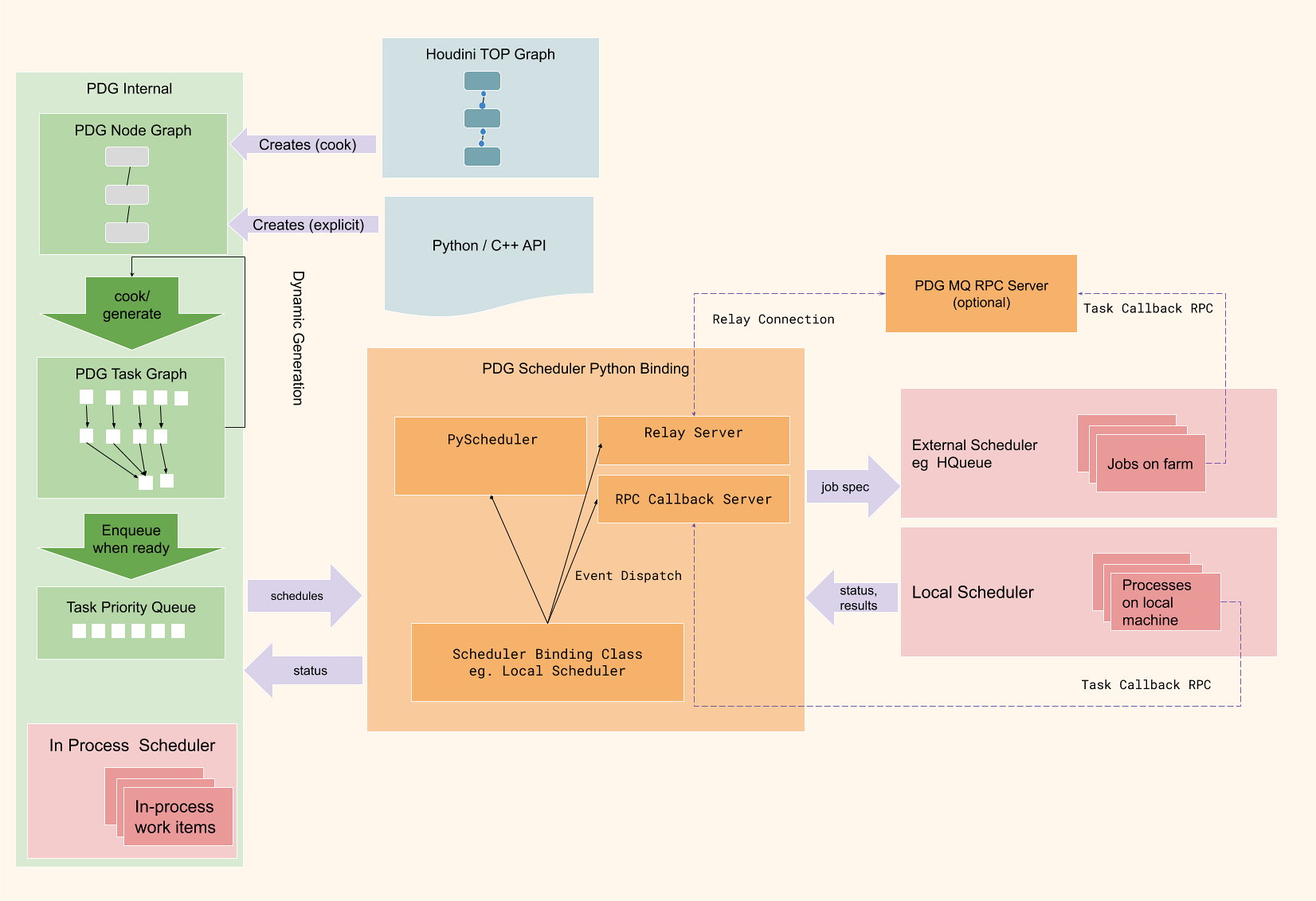
This diagram shows the flow of work from the initial cook of the Houdini TOP network to the execution of jobs on the local machine or farm.
The green boxes represent the PDG Graph Core which manages nodes, work items and dependencies but does not execute any work.
The pink blocks are where the jobs are actually executed, and the orange PDG Scheduler Python Binding is the system that converts the PDG work items to farm scheduler jobs and monitors their progress.
The PDG MQ RPC Server is a program that can be used to multiplex status and result RPC calls from jobs back to the scheduler binding. This is useful to avoid firewall and networking issues between the artist machine and the machines the jobs are executing on.
Reducing work item overhead ¶
Starting operations in separate processes, scheduling work on the farm, and moving data across the network filesystem all add overhead to work you do in TOPs. Some nodes have options to do small jobs inside the process cooking the graph, and you can override small work items to run on the same machine instead of being scheduled on the farm.
However, even for an ![]() HDA Processor node running locally, if the asset cooks quickly, the overhead of running it in a separate process still kills overall performance. There are few things you can do to optimize or work around this:
HDA Processor node running locally, if the asset cooks quickly, the overhead of running it in a separate process still kills overall performance. There are few things you can do to optimize or work around this:
-
Use a
 ROP Geometry node to generate geometry instead of HDA Processor, and do your wedging using time/frame number.
ROP Geometry node to generate geometry instead of HDA Processor, and do your wedging using time/frame number.In the same HIP file as your TOP Network, instantiate your asset, and point a ROP Geometry node at the SOP network. On the ROP Geometry node, turn on All Frames in One Batch on the ROP Fetch tab. That will create a single process that cooks the full frame range one frame at a time, which is typically used for simulations but is often more efficient for light-weight geometry jobs.
You can also play with a custom batch size. For example, instead of All Frames in One Batch, you could use 20 frames per batch.
-
If possible, you can try using the
 Invoke node instead of HDA Processor. The Invoke node cooks a SOP chain in the process cooking the graph instead of in its own process. The limitation is that you can only use it on a compiled block. For small/quick operations this is much more efficient.
Invoke node instead of HDA Processor. The Invoke node cooks a SOP chain in the process cooking the graph instead of in its own process. The limitation is that you can only use it on a compiled block. For small/quick operations this is much more efficient. -
When using
Local Scheduler you can use Services to massivly speed up  HDA Processor and ROP-Fetch-based work.
HDA Processor and ROP-Fetch-based work. -
When using a farm, it may be more efficient to run small jobs on your local machine by setting the Node’s scheduler override to a
Local scheduler. You can also try increasing the Total Slots on the Local Scheduler. The default maximum is very low (number of cores / 4) to avoid slowing down the local machine. With a higher Total Slots, more local jobs will run concurrently.
| See also |