新しいサンプルベースのML系ノードは、Houdini内から完全に機械学習のセットアップを作成することができます。 新しい汎用MLトレーニングノードを使用することで、トレーニングスクリプトを記述する必要なく、大規模な回帰問題を解決することができます。
サンプルベースのML系ツールセットは2つのパートで構成されています:
-
データセットの生成、データセットの前処理、データセットのディスクへの書き込み、ディスクからのデータセットの読み込み、推論、最近傍クエリの実行を行なうためのSOPツール。
-
それらのSOPツールで使用するために設計されたTOPトレーニングノード。
サンプルベースのML系ノードは以下のノードで構成されています:
パックプリミティブセットを生成します。 各パックプリミティブには、特定のアトリビュートがランダムなジオメトリが含まれています。 各パックプリミティブがデータ生成工程の入力に指定することができます。
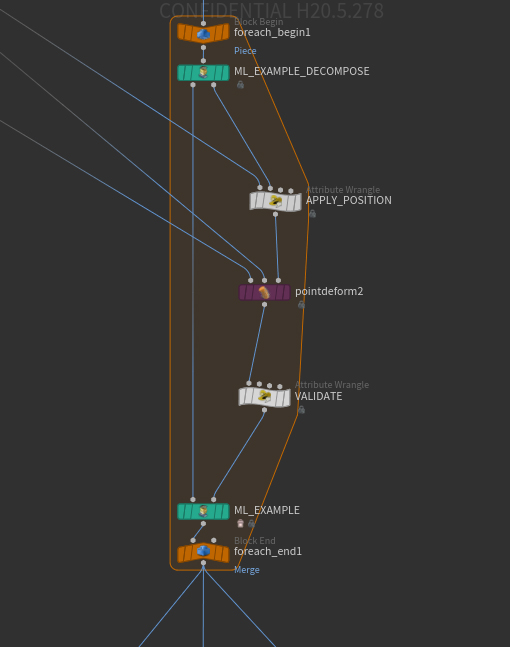
入力コンポーネント(例えば、![]() ML Attribute Generateで生成されたコンポーネント)とターゲットコンポーネント(その入力コンポーネントのプロシージャルネットワークの出力)を組み合わせてサンプルを生成します。
ML Attribute Generateで生成されたコンポーネント)とターゲットコンポーネント(その入力コンポーネントのプロシージャルネットワークの出力)を組み合わせてサンプルを生成します。
サンプルを入力コンポーネントとターゲットコンポーネントに分解します。
これは、サンプルの前処理、例えば、![]() Principal Component Analysisを使用する時に役立ちます。
Principal Component Analysisを使用する時に役立ちます。
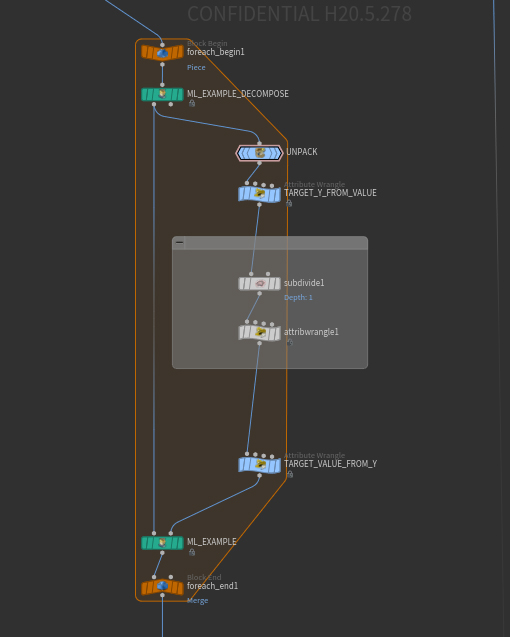
サンプルのコレクションをパーツ(サブコレクション)に分割します。 これは、データ生成の最適化とデータの前処理に役立ち、メモリ使用量と速度のバランスを調整することができます。
サンプルのコレクションから、指定したインデックスでの単一サンプルを抽出します。 これは、TOP内からサンプルを処理する時に役立ちます。 また、これは視覚化やトラブル対応にも役立つノードです。
![]() ML Regression Trainを使ってトレーニングできるように、サンプルのコレクションをRawデータファイルに書き込みます。
ML Regression Trainを使ってトレーニングできるように、サンプルのコレクションをRawデータファイルに書き込みます。
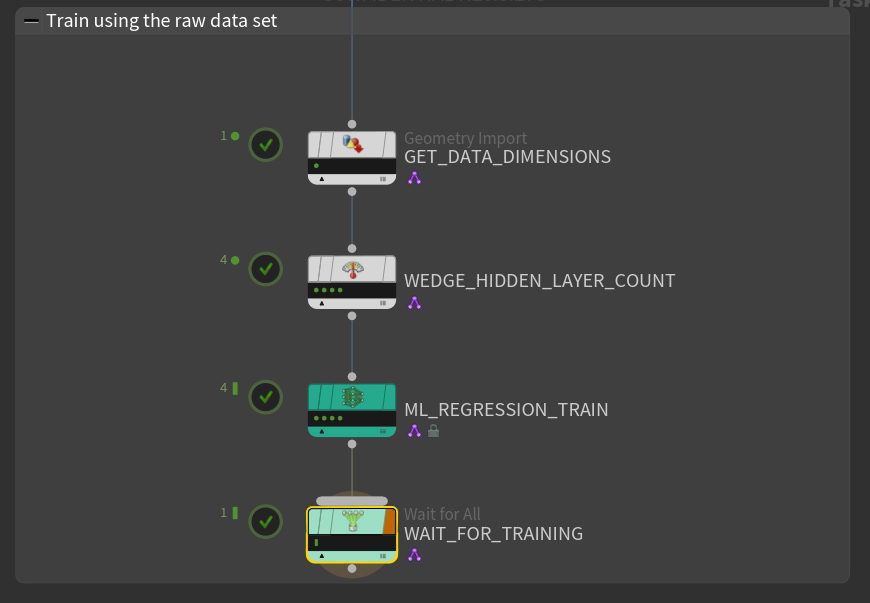
![]() ML Example Outputを使って以前にディスクに書き出されたサンプルコレクション上のモデルをトレーニングします(Feedforward Neural Network:順伝播型ニューラルネットワーク)。
ML Example Outputを使って以前にディスクに書き出されたサンプルコレクション上のモデルをトレーニングします(Feedforward Neural Network:順伝播型ニューラルネットワーク)。
![]() ML Regression Trainでトレーニングされたモデルを1つ以上の(まだ見たことのない)入力に適用します。
ML Regression Trainでトレーニングされたモデルを1つ以上の(まだ見たことのない)入力に適用します。
最近傍検索を使用して、特定のクエリ入力に最も近いサンプルコレクション内の入力コンポーネントを見つけ、それに呼応するターゲットコンポーネントを返します。 これは、ディープラーニングではないMLのサンプルです。
![]() ML Example Outputを使用して以前に書き出されたサンプルコレクションをディスクから読み込みます。
ML Example Outputを使用して以前に書き出されたサンプルコレクションをディスクから読み込みます。
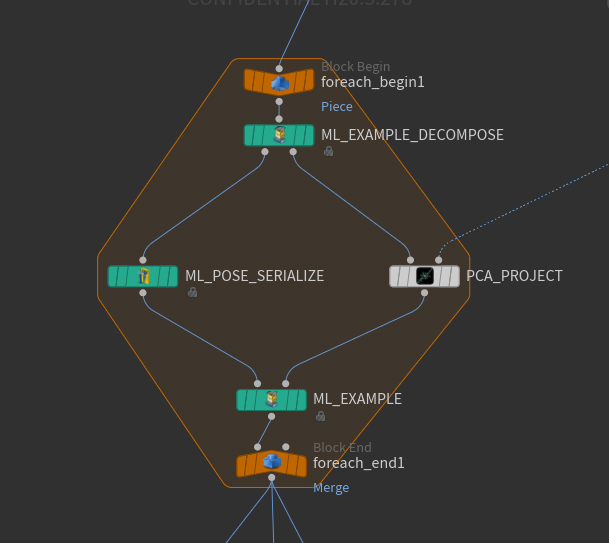
このアダプタノードによって、サンプルベースのMLツールでアニメーションを扱うことができるようになります。 これは、ランダムなリグポーズセットを生成します。それをリグ入力に指定することで、機械学習を適用することができます。
このアダプタノードによって、サンプルベースのMLツールでアニメーションを扱うことができるようになります。
これは、リグポーズをデータセットに入るようにするために浮動小数点Pointアトリビュートに変換します。
この同じノードは、![]() ML Regression Inferenceの入力も準備します。
ML Regression Inferenceの入力も準備します。