はじめに
このチュートリアルでは、Houdini 20.5 と同時にリリースされた、グルームデフォーマ構築用のサンプルベースの機械学習 (ML) ノードの使い方を解説していきます。シーンを見れば、ML 関連のノードを配置しパラメータを設定するだけで、訓練用のカスタムスクリプトを書かずとも、Houdini 内で多種多様な ML セットアップを構築できるのがわかるでしょう。このチュートリアルは、Content Library 内でリリースされたプロジェクトファイルの補足として作成されたものです。このページからもファイルをダウンロードできます。
このシステムは ML Deformer H20.5 に基づき、グルーム作業の拡張機能として構築されました。
このプロジェクトは、トロントで行われた SideFX 主催の Houdini HIVE Horizon イベントの際に筆者が発表したプロジェクトの1つです。講演の全編はこちらでご覧になれます。
PCA Shenanigans and How to ML | Jakob Ringler | Houdini Horizon
このテキストでは、より具体的なセットアップの詳細を解説しています。

概要
一言でまとめると、ここでのゴールは、高コストのシミュレーションやプロシージャルなセットアップに頼らず、機械学習モデルを使うことでキャラクタやクリーチャーのファーの変形を予測することです。
問題
ヘアをそのまま変形させたり、リニアに変形させたりしようとすると、幾つかの問題に頻繁に遭遇します。特にジョイント領域周辺では、ジョイント上に生成されたヘアが下層のファーにめり込んでしまう相貫の問題が多発します (下図2番目のポーズを参照)。理想的には、ガイドがきれいに重なり、より良いボリューム保存をしたいところですが、それを実行すると計算のコストが上がる可能性があり、多くの場合、シミュレーションの他に、ひとつまたは複数の工程にわたるポスト処理が必要になります。
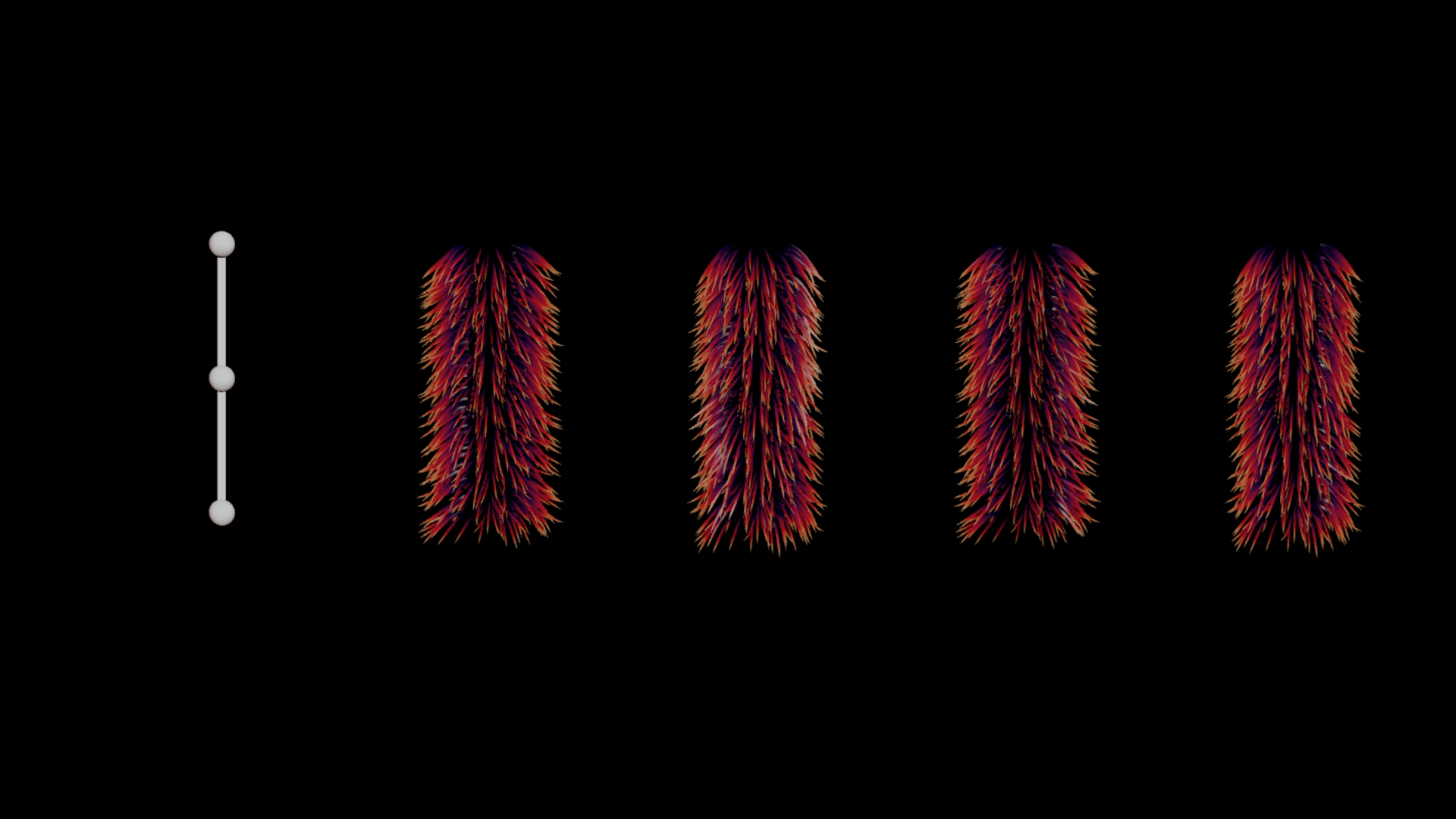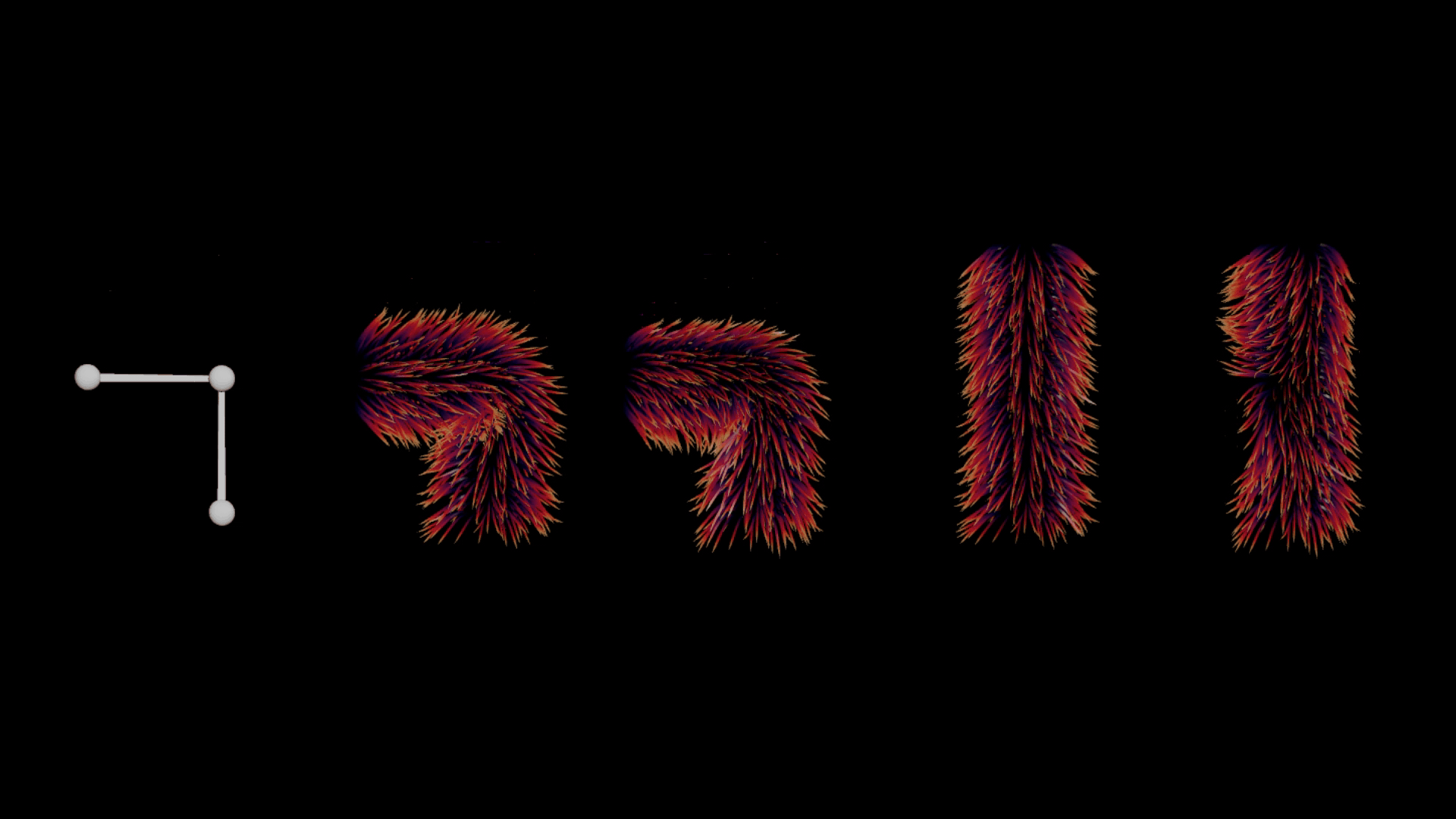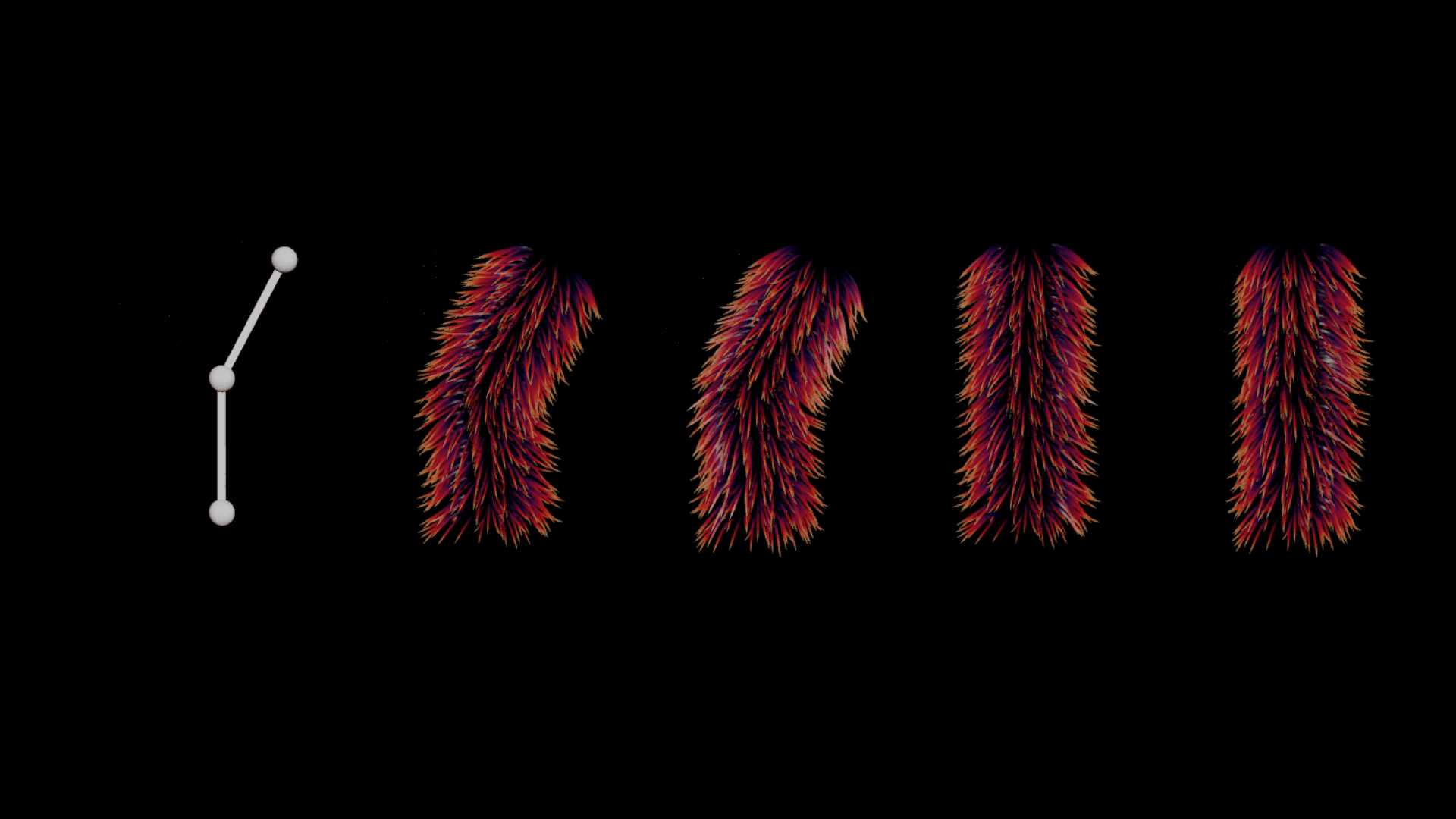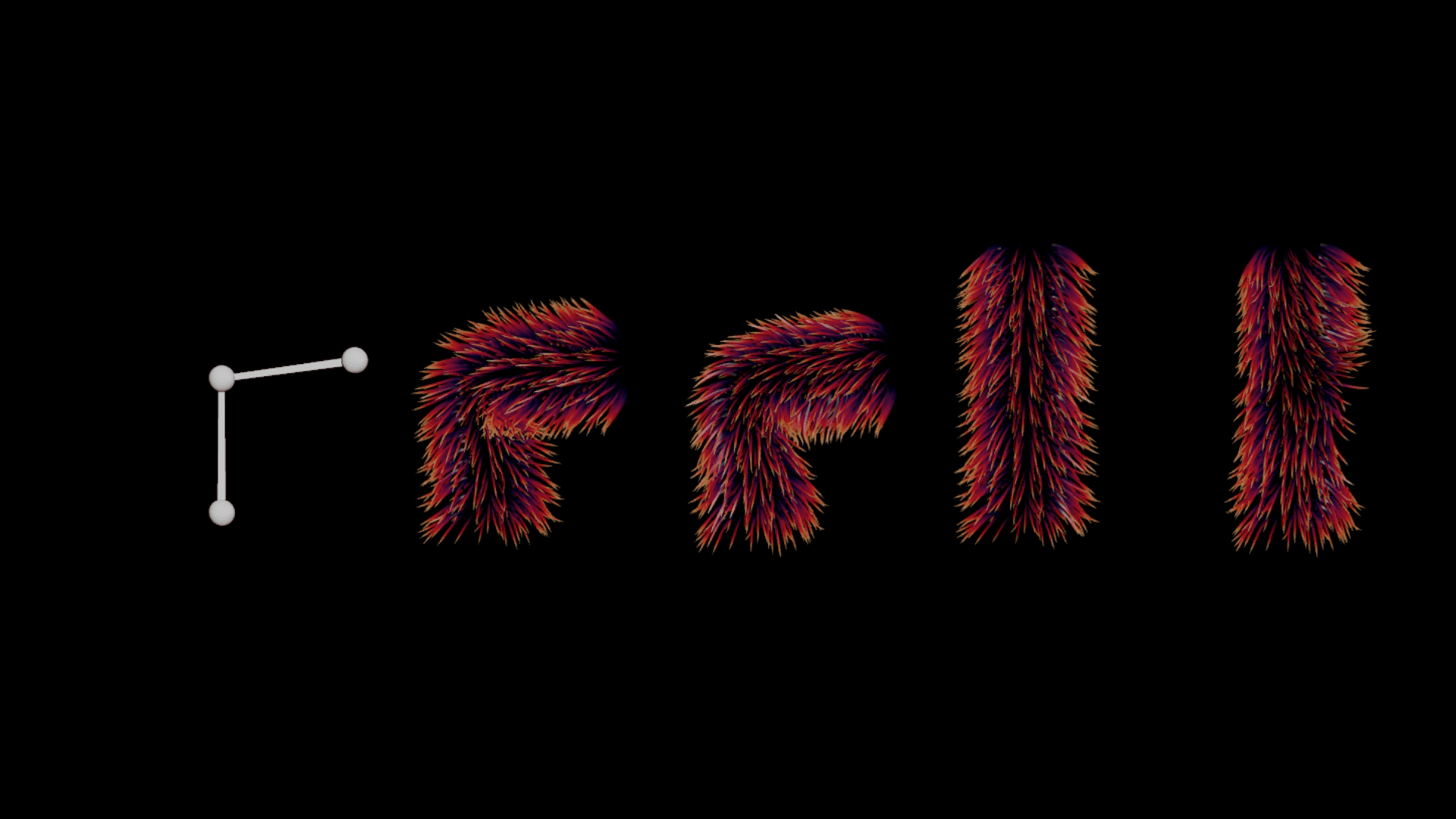
左から右:リグ、デフォルトのガイドの変形、望ましい変形 (準静的 (Quasi-Static) シミュレーション)、静止状態のガイド、rest 空間における変位
解決法
ここでの目標は、ML モデルを使って、ガイドに適用する変形をリグポーズを元に予測させることです。このモデルに、各リグのジョイントの回転情報から、各ポーズの変形後のガイドのおおよその位置をマッピングすることを学ばせていきます。
その際、大量の学習用サンプルが必要になります。一般的なパイプラインは以下のようになります。

2. 設定したジョイント制限を基に大量のランダムポーズを生成する (余裕を持たせるため少なくとも 3000 を想定)
3. 各ポーズに対し、グラウンドトゥルース/優良なガイド変形をシミュレートする
4. 全ての変形を収集し、そのデータを圧縮して PCA サブ空間に格納する (概念として難解な工程)
5. 事前処理の済んだ完全なデータセットをディスクに格納する
6. TOPs 内で機械学習モデルの訓練をする (実際には易しい工程)
データの生成
全ての訓練データは、生成を開始するにあたり、以下の2点が必要です。
2. ガイドのセット
ジョイント制限
各ジョイントに固定値を設定してもよいですが (例:30)、リグのモーションクリップが幾つかある場合、そこから読み取れる動作範囲を元にジョイント制限をプロシージャルに設定する方が望ましいです。これには、Configure Joint Limits SOP を使います。
ポーズのランダム化
Houdini 20.5 には、この処理を効率化するための ML Pose Generate SOP が実装されています。この新しいノードは、既存のジョイント制限を用い、 ガウス分布に従ってランダムポーズを生成します。つまり、極端なポーズよりも一般的なポーズの方がより多く生成されるので、頻繁に使うポーズで優れたパフォーマンスを発揮するモデルを訓練するうえで望ましいです。
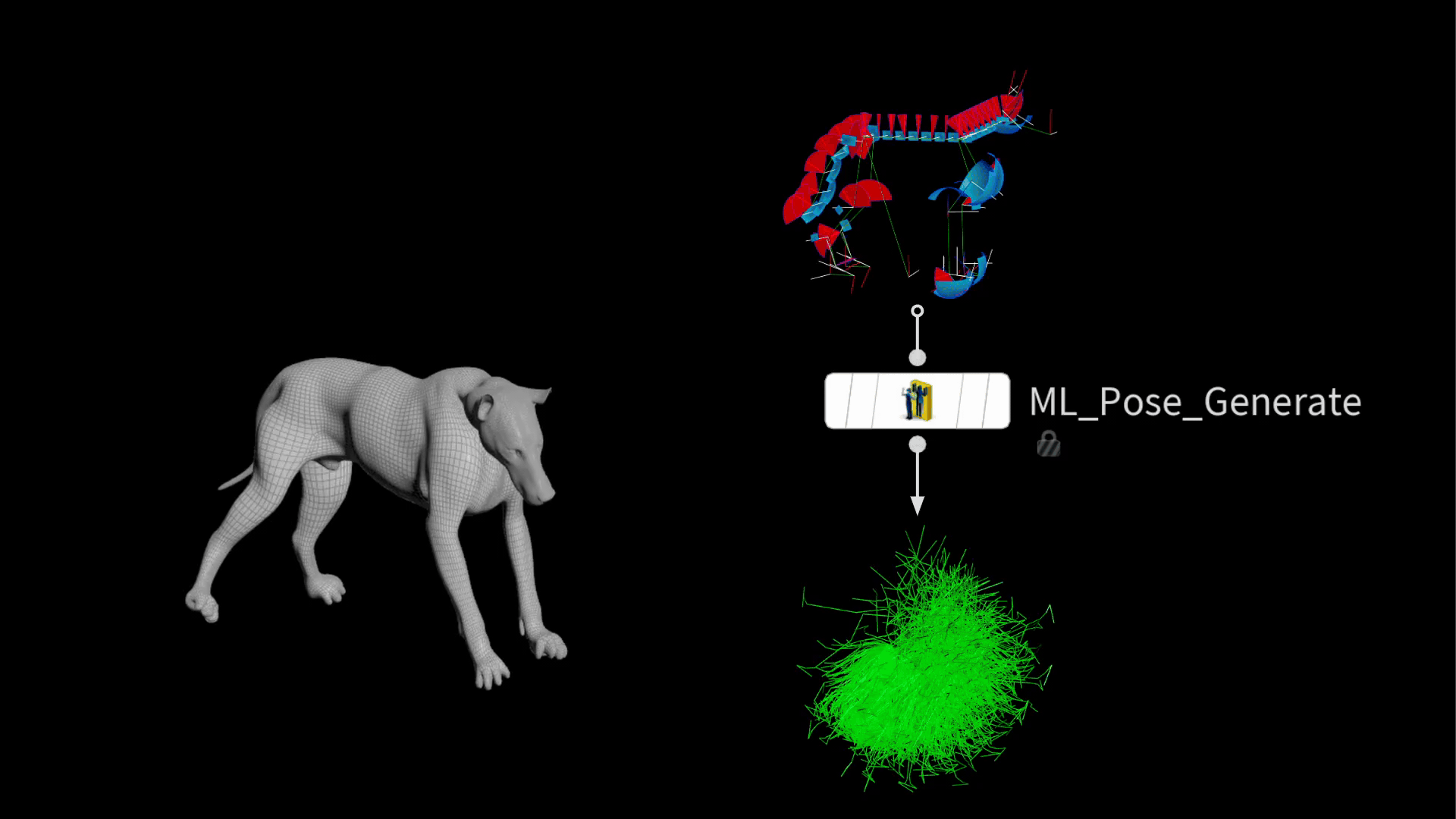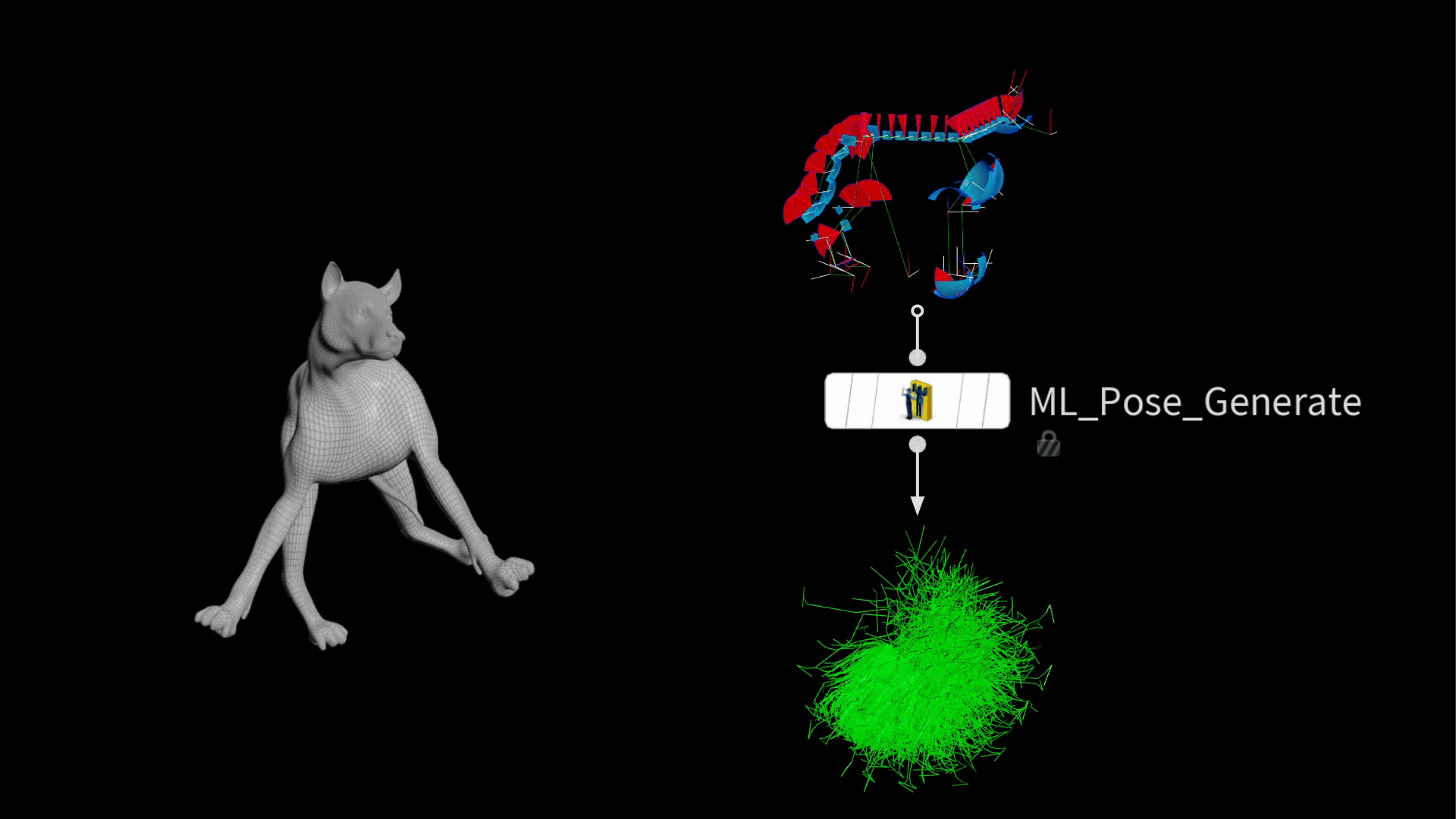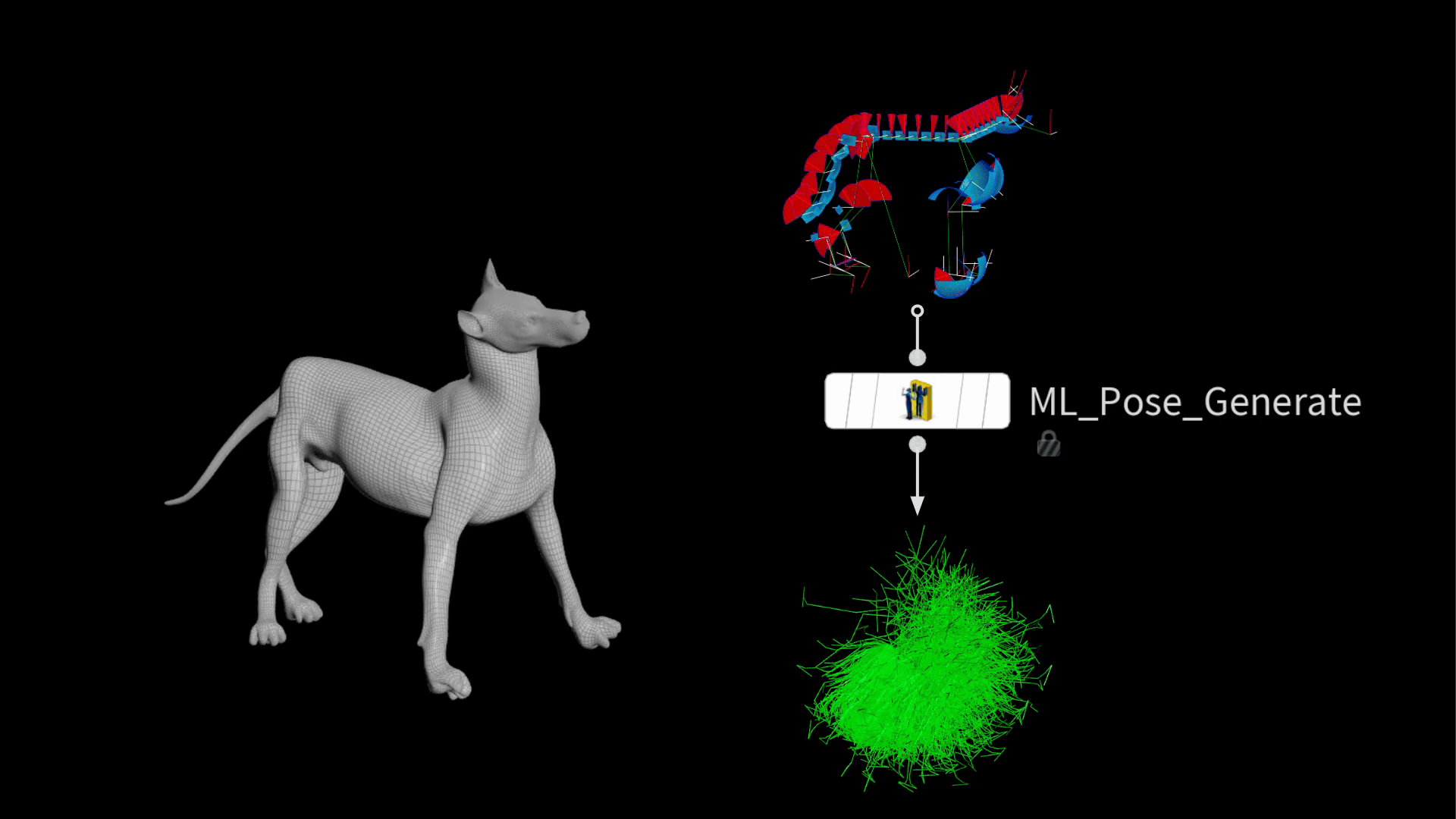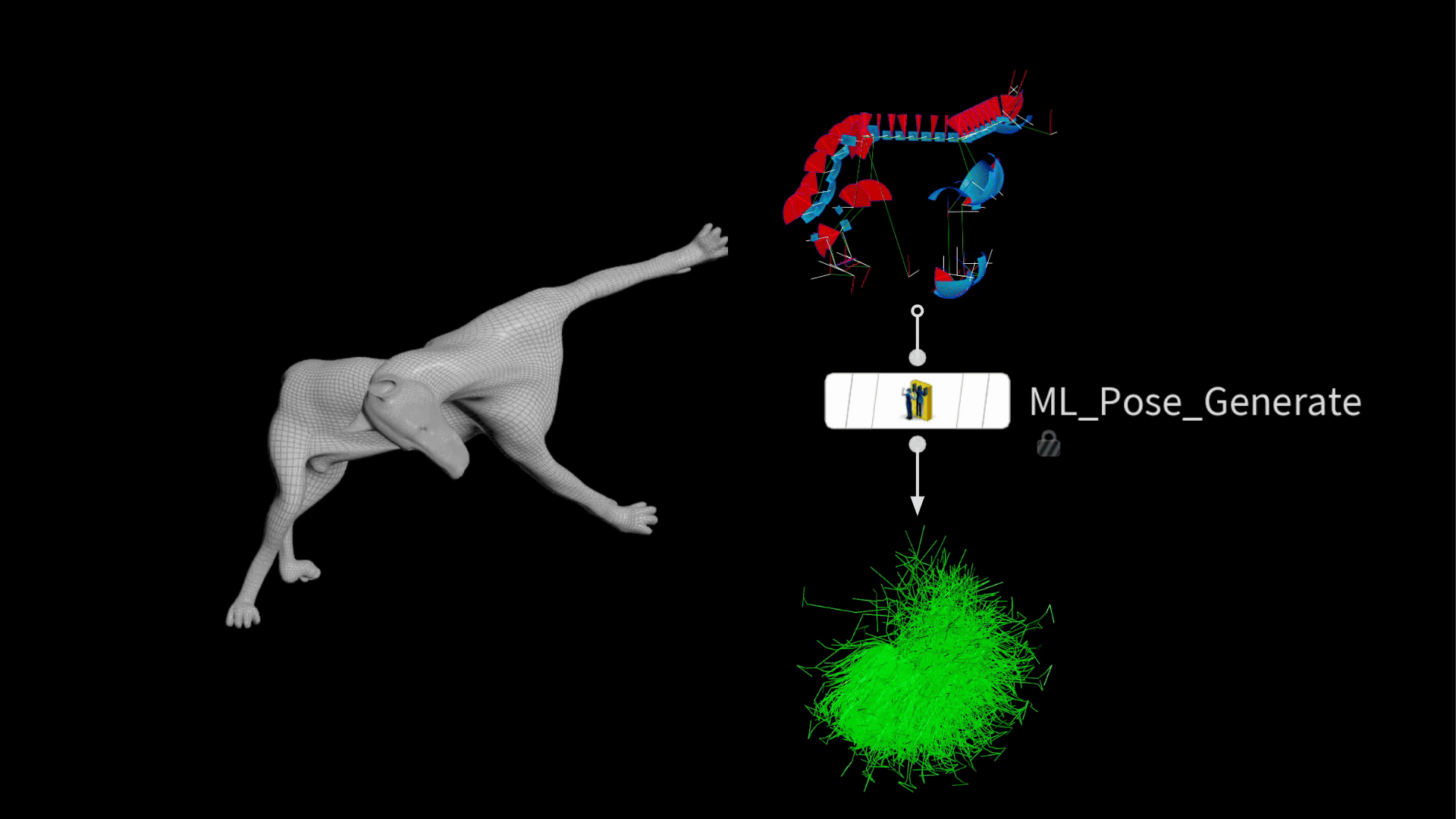
出力される時は、大量のリグポーズを含むパッケージが積み重なっています。
シミュレーションの反復
この工程では、TOPs を使って生成されたポーズを1つひとつ実行し、それぞれに応じた優良なガイドの変形結果を生成/シミュレートしていきます。
ほとんどどのような手法でも使えますが、何点かの制約があります。
それは、結果が決定論的/プロシージャル/準静的であることです。
つまり、慣性を持たせることはできません (揺れ、オーバーシュート、シミュレーション由来のその他の効果的な動きなど)。また、同じ入力で実行したら必ず同じ結果にならねばなりません。入出力間の関係の整合性がとれていて、同様の入力が近しい関係の結果を返す必要があります。つまり、ほぼ同じ入力の時に、結果が大幅に異なるような手法は避けなければなりません。
ここでは準静的四面体シミュレーションと、交差回避パスを組み合わせ、ヘアおよび皮膚から構築したベロシティフィールドによって、ガイドを移流させていきます。
ポーズのブレンドアニメーションの作成
この工程では、静止ポーズをリグのターゲットポーズへとブレンドさせて、シミュレーションの駆動に使うアニメーションを作ります。

準静的四面体シミュレーション (Vellum)

ファーの主要部分をシミュレーションするには、ガイドを元に、ファーのボリュームと変形をシミュレートするための四面体のケージを構築します。これは、ガイド間での衝突を回避し、適切なファーの重なりという意図通りの効果を得る上で、大いに役立ちます。
四面体ケージの生成には、以下の簡単な VDB 操作を用いました。
ガイド > パーティクルを VDB に変換 > 形状変更 (Reshape)、拡張 (Dilate)、閉じる、縮小 (Erode) >Tet Conform
四面体のシミュレーションは Vellum の準静的モードで実行します。赤い内部のポイントがアニメーションに固定されソフトボディに動きをつけます。


ポイントデフォームによる変形を適用すると、エッジのジャギーが全て消え、大部分の相貫も解消されます。グルーム全体のボリューム保存も大幅に改善されています。
ベロシティ移流による交差の解消
残っているガイドの交差を一掃するため、皮膚メッシュの法線とガイドの接線から構築したベロシティフィールドを使って、ガイドを移流させます。これにより、ベロシティフィールドの性質上、基本的にはガイドが自ら交差を消し、同時に流れも少し整います。これは、CFX 自動化パイプラインに関する Animal Logic によるトークで初めて知ったテクニックです。

グラウンドトゥルースの例
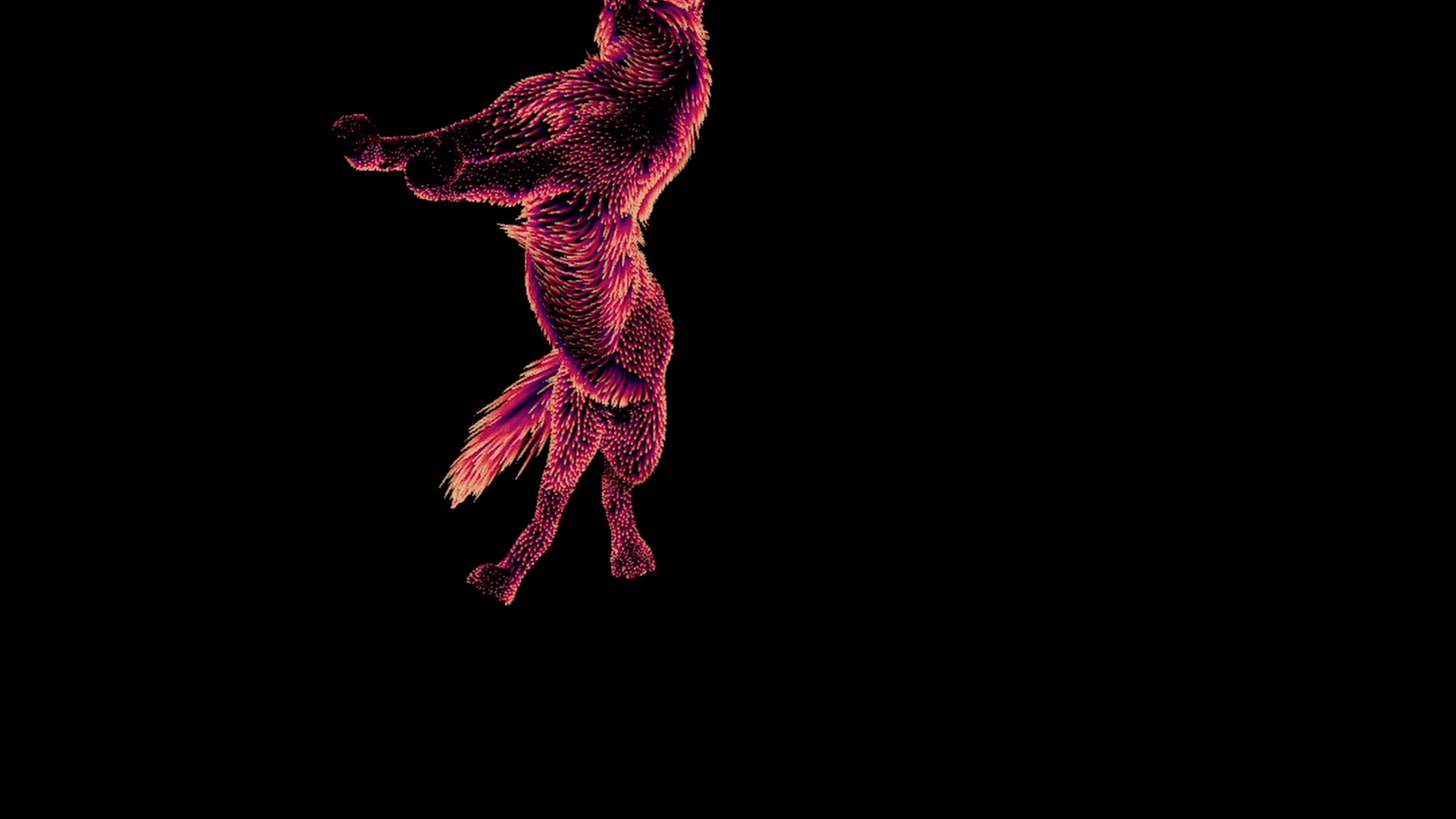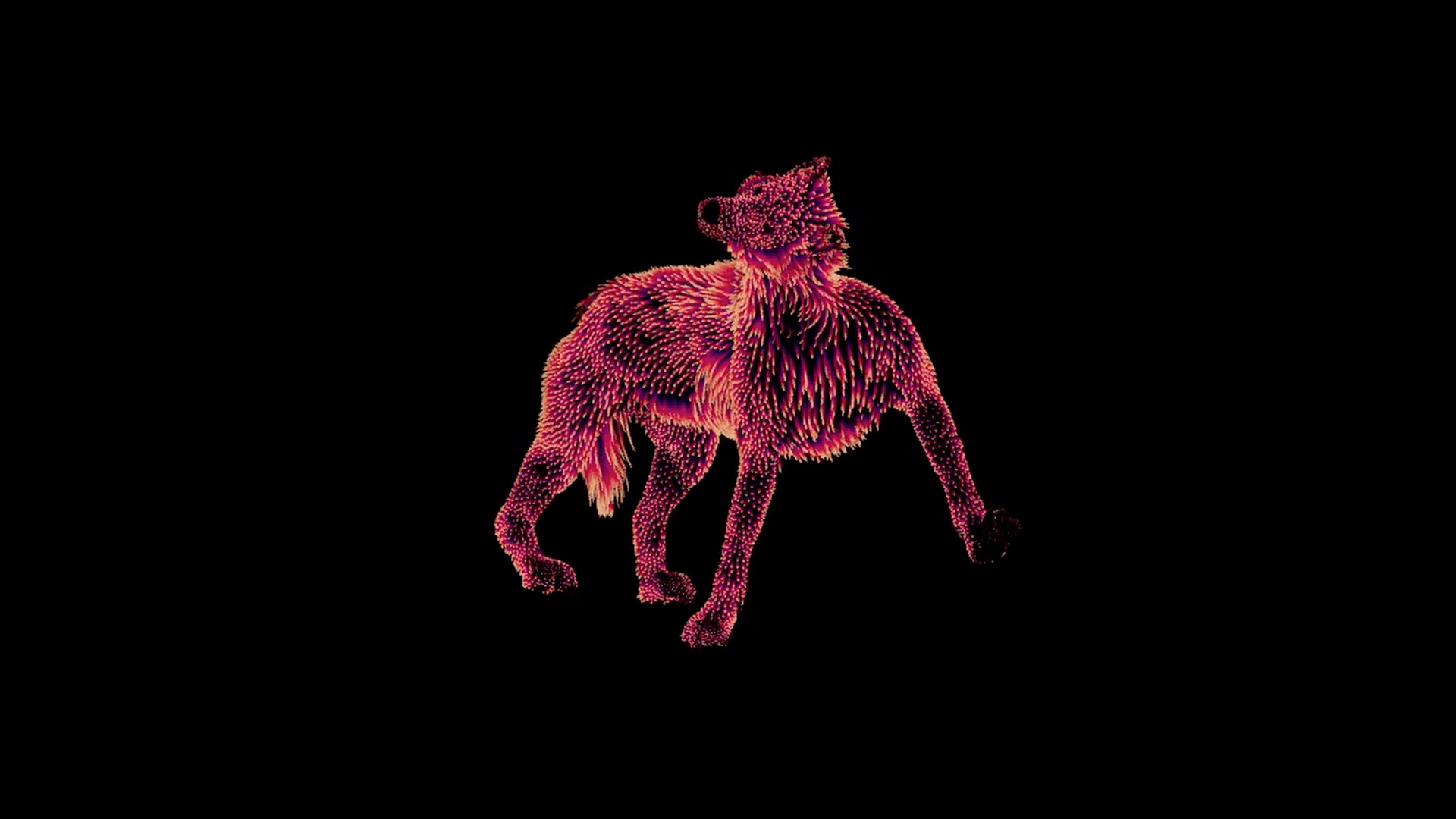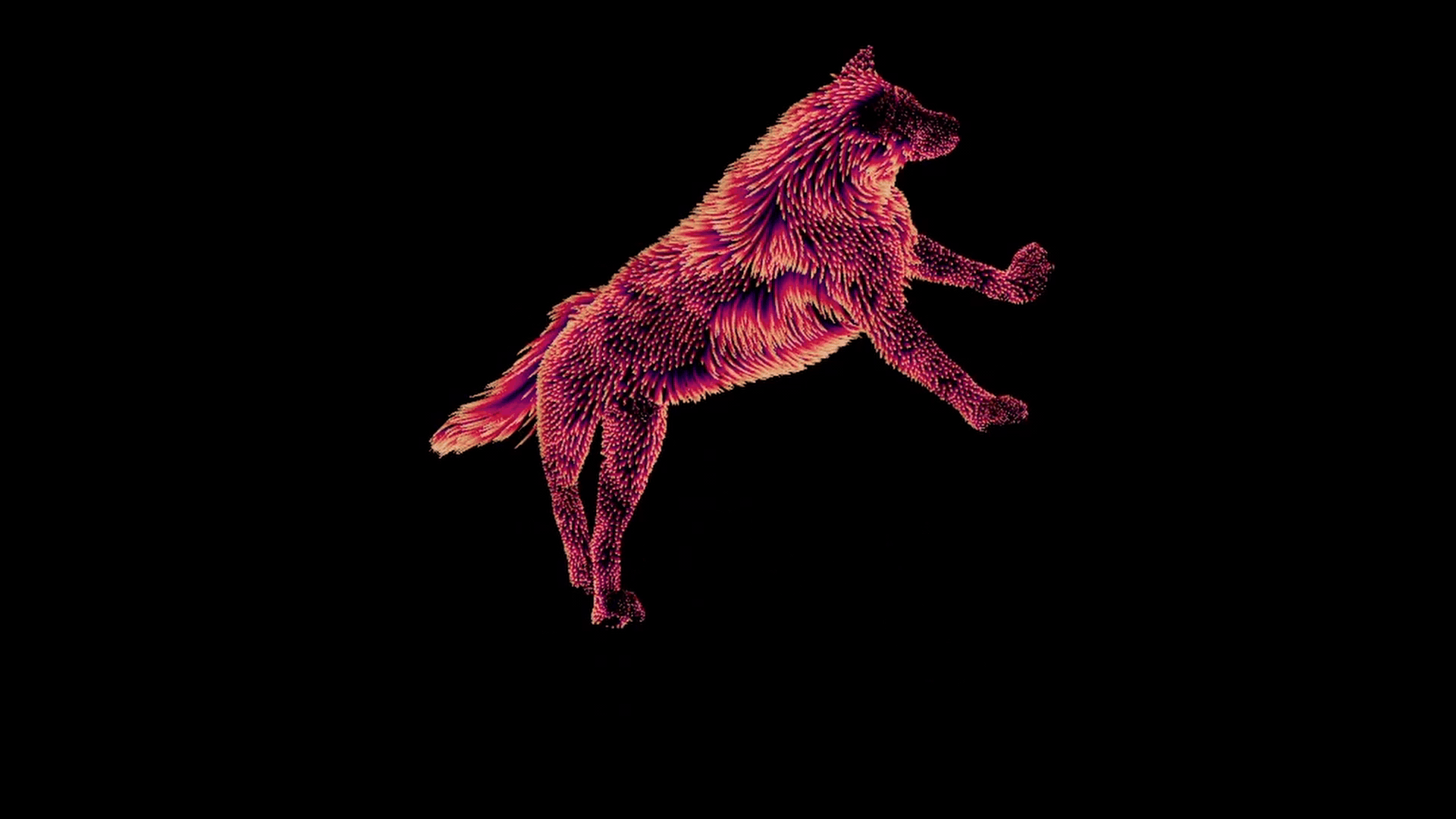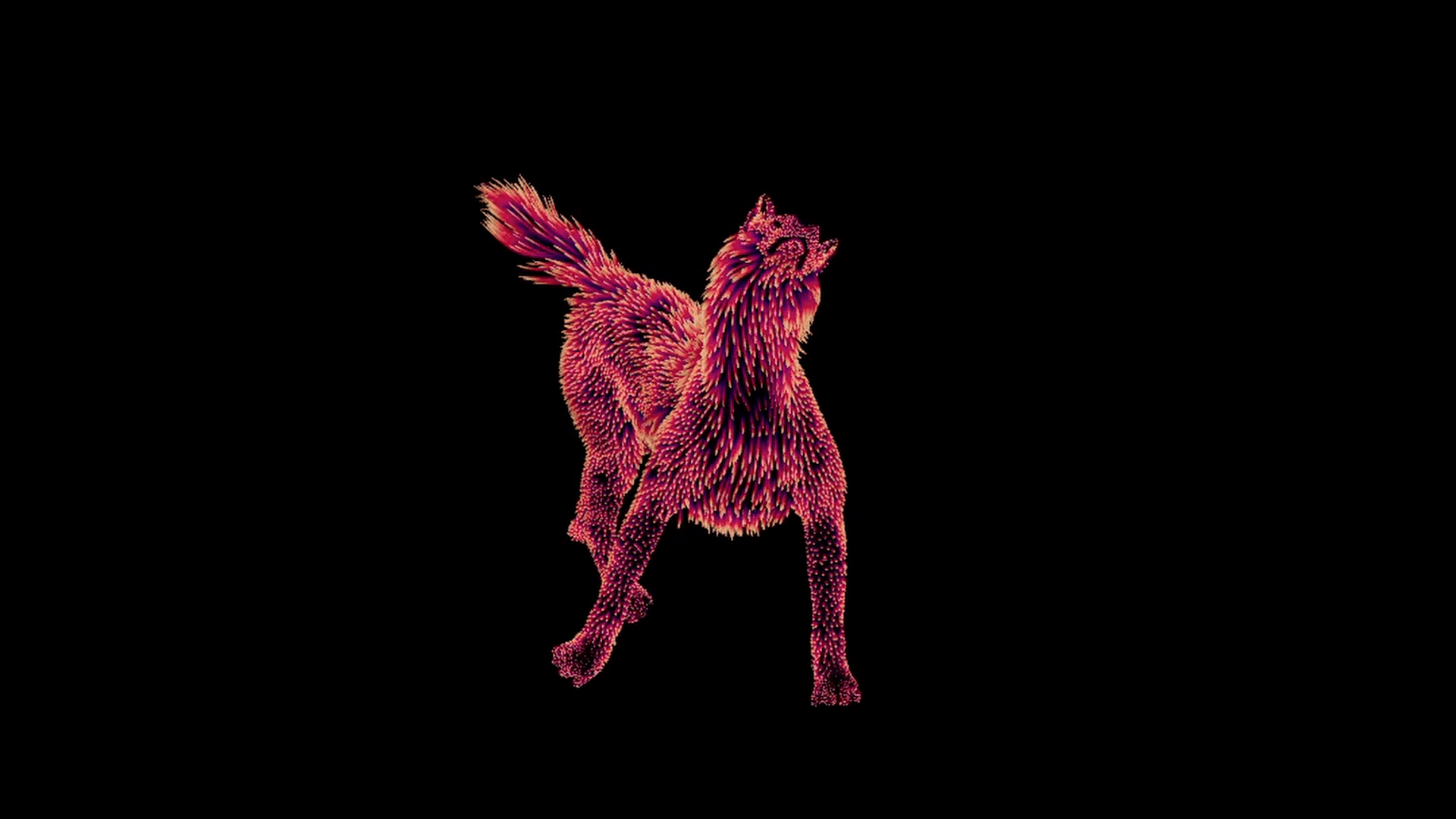
それが終わると、各ポーズに対し、適切な変形のついた一組のガイドができあがります。
rest 空間における変位計算
次に、デフォルトの Guide Deform SOP を使って、これらのポーズを1つひとつ rest 空間に戻していきます。rest 空間では Shape Diff SOP を使って、変形後のガイド上の各ポイントと、静止状態のガイドとの差を計算します。これによって得られるクリーンなポイントクラウドを、リグポーズと一緒に訓練用サンプルとして格納します。
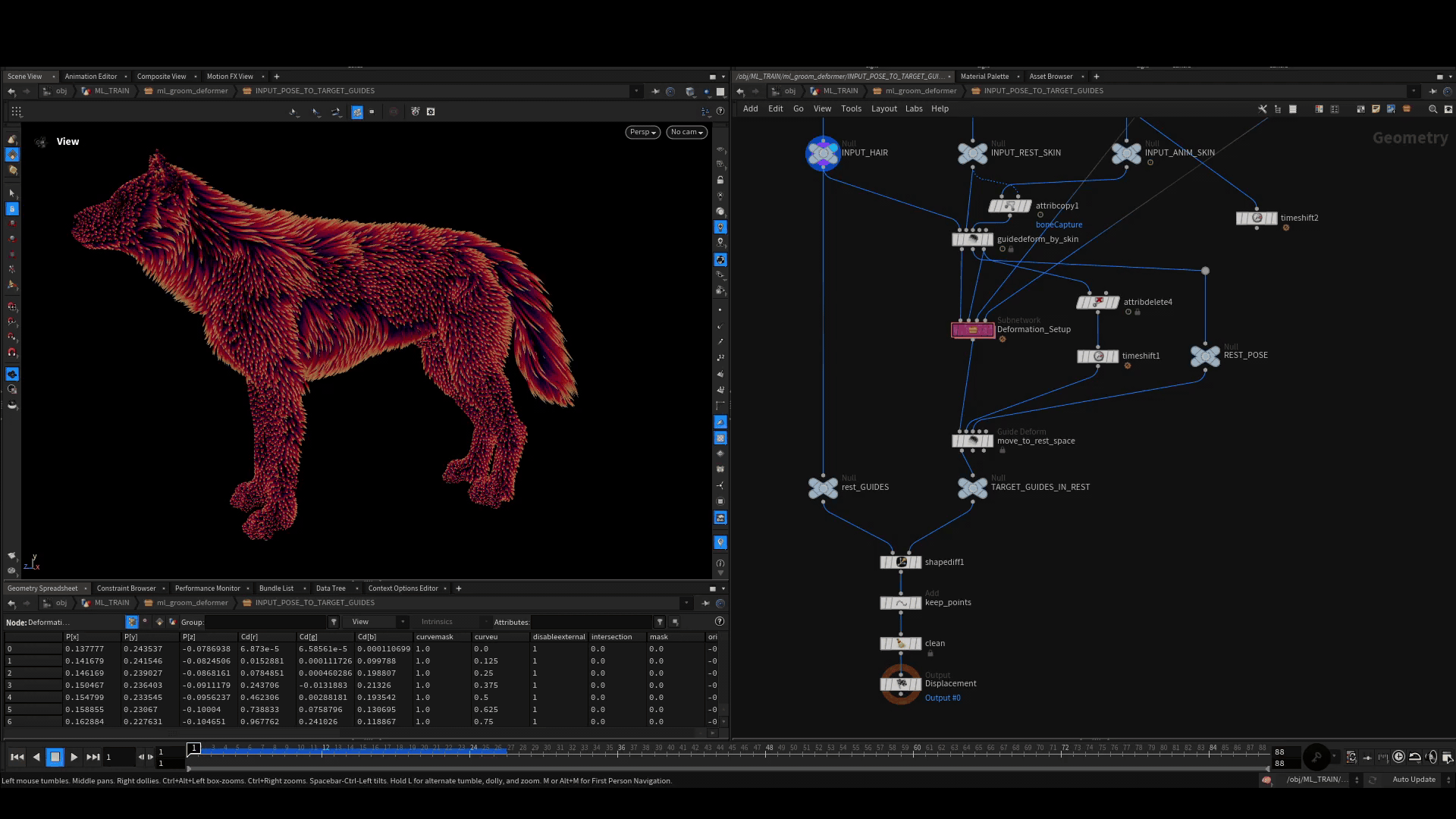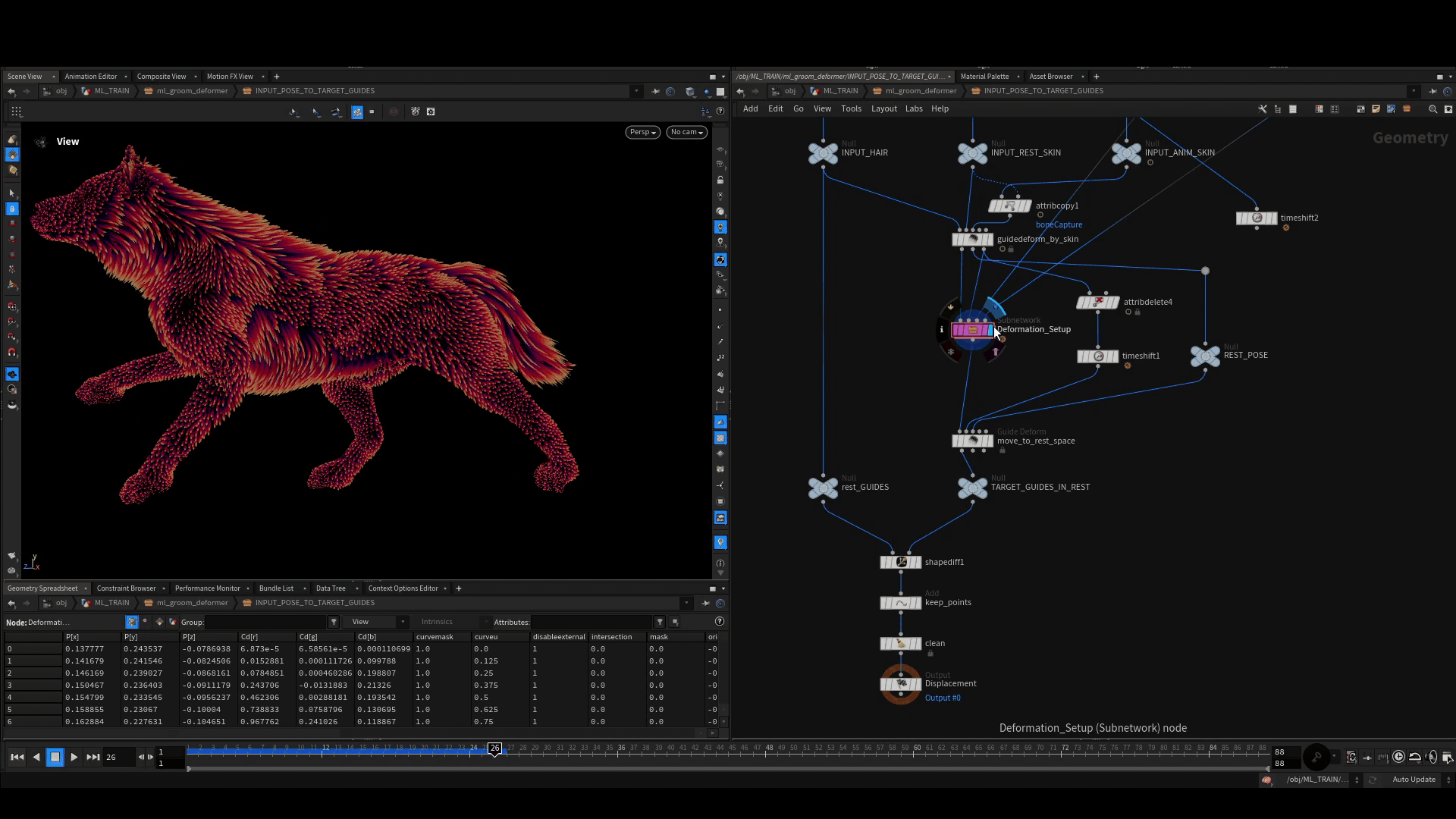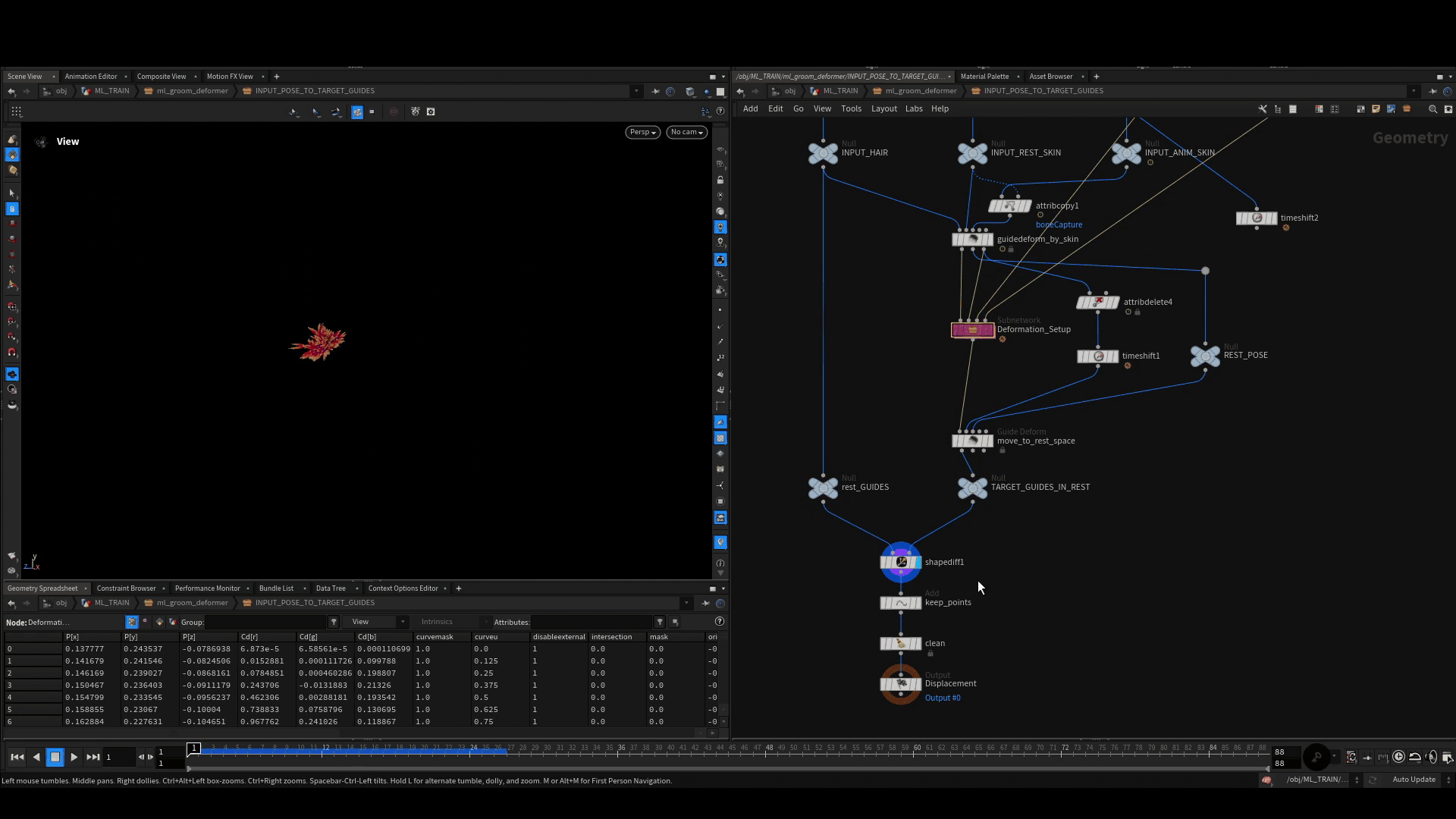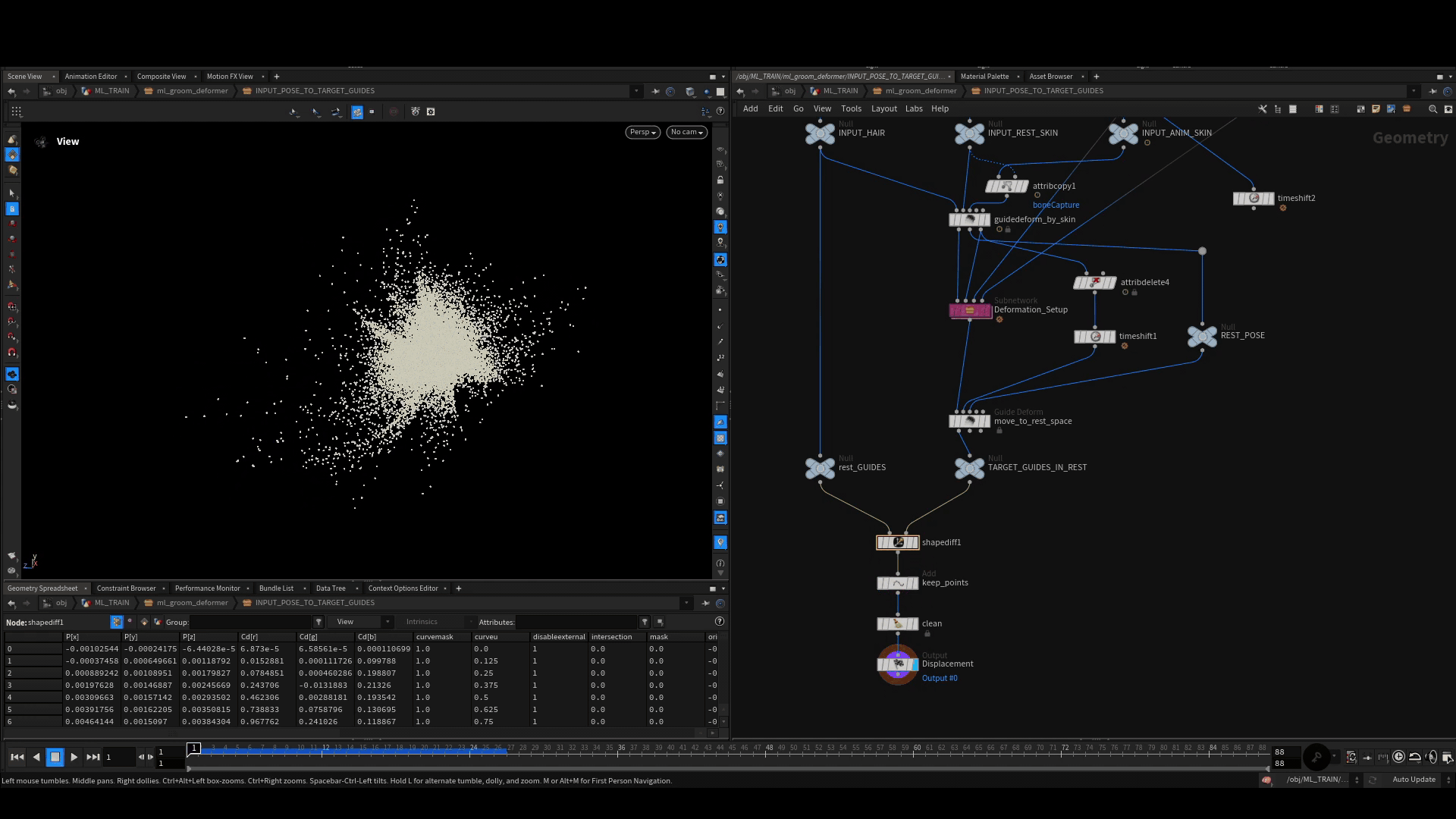
サンプルの格納
全てのポーズのシミュレーションが完了して変位が生成されたら、Houdini で ML Example と呼ばれるものの構築に進みます。これは通常、データサンプルと呼ばれ、ひとつの入力とひとつのターゲットから構成されています。このサンプルをたくさん作り、訓練中のネットワークに見せてやると (うまくいけば) 目下のタスクを学習させることができます。
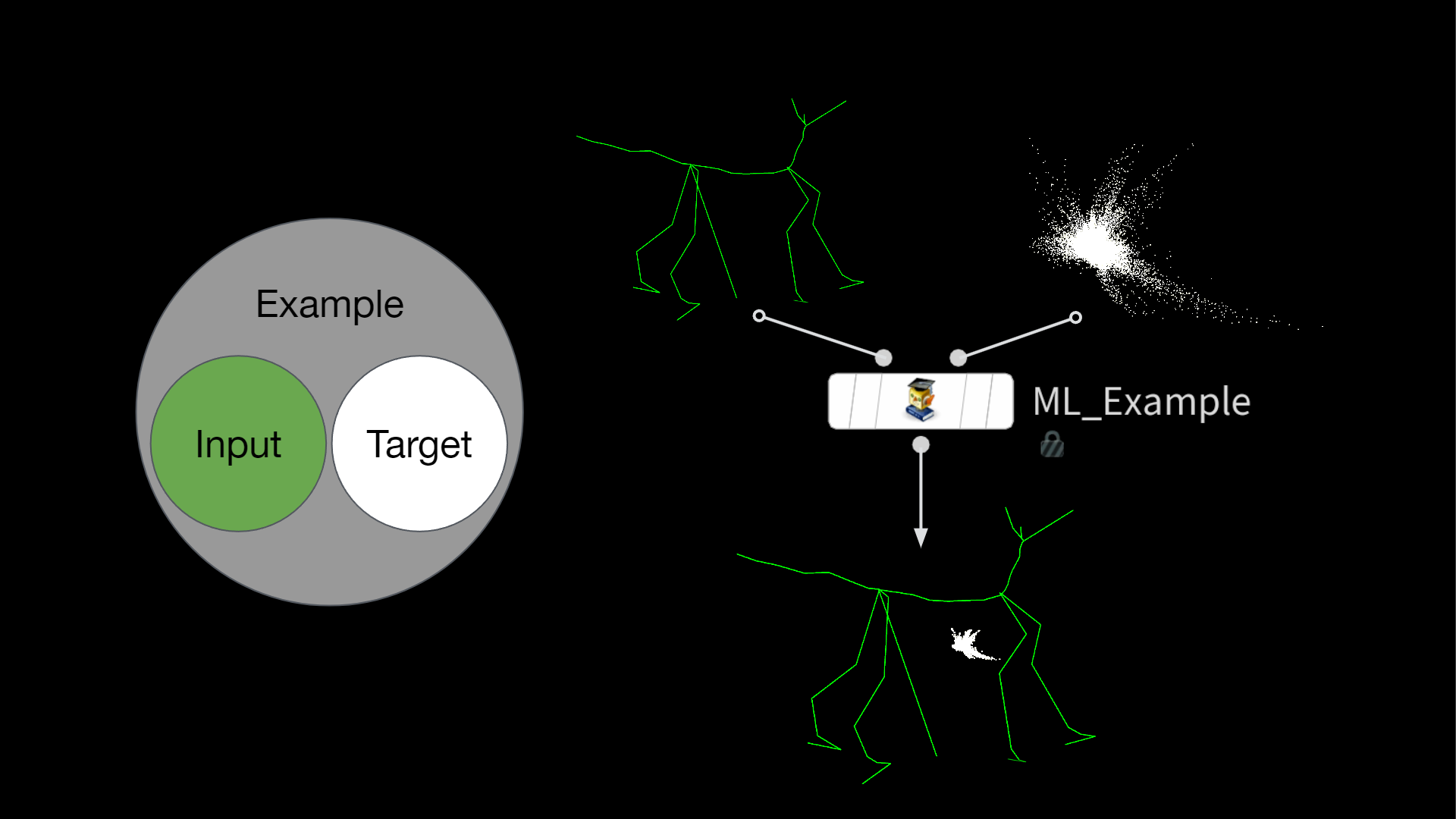
PCA サブ空間の圧縮とシリアライズ
全てのポーズの変位を生成したら、そのポイントを持ち込んでひとまとめにマージし、PCA サブ空間を計算していきます。
サブ空間の生成
PCA による高度な計算で 4000 のサンプルを圧縮させ、より数の少ないコンポーネントにしていきます。今回の場合、より数の少ないブレンドシェイプを作るようなものと考えてください。このブレンドシェイプは変位群で構成されており (その変位を正しく組めば) 全ての入力を正確に再構築できます。

この PCA で生成されたポイントクラウドは、新たなコンポーネント (作成されたブレンドシェイプ) が全て積み重なっています。Houdini 内で特に分けられていません (パックされていたり、ID が付与されている等ではありません)。各コンポーネントのポイントは、サンプルのサイズを把握することで判断します。例えば、使用中のデータセットに含まれるポイントの数が 100,000 である場合、そのポイントのリストを解析すればコンポーネントを特定できます。ひとつめのコンポーネントは 0 から 99,999 (ptnum 100,000 -1) のポイントで構成されており、ふたつめは 100,000 から 199,999 (ptnum 200,000-1) 、という具合です。
サンプルごとのウェイトを計算する
各サンプルで同じ計算を繰り返したら、PCA に、変位ポイントをサブ空間に「投影」(ウェイト計算に関する PCA の数学用語) させます。これにより、サブ空間内のコンポーネントの量に合ったウェイトのリストが返されます。
これらのウェイトを、後ほどサブ空間のポイントクラウドに適用すると、元の変位のポイントクラウドを再構築することができます (少なくとも十分に近いものを再構築できます)。
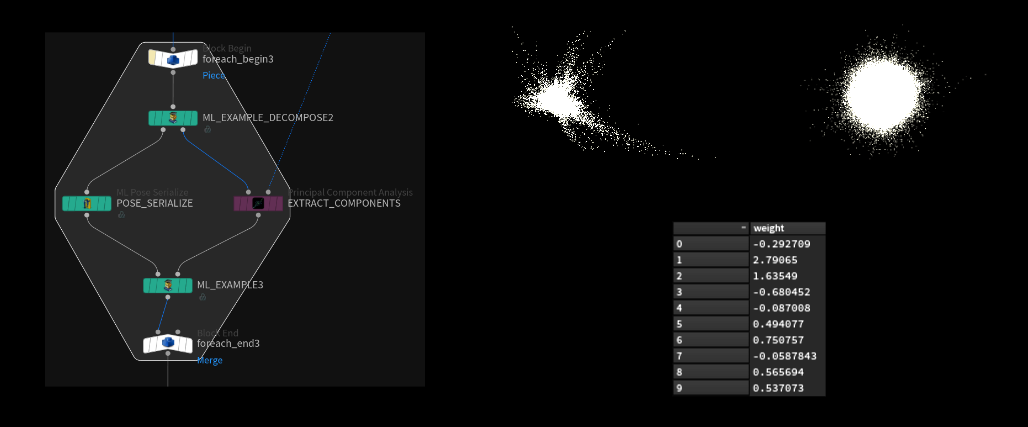
100パーセントの再構築はできませんが、わずか数百のコンポーネントで、95パーセント超のレベルを達成可能です。
ヘアのガイドの場合は、ヘアのガイドの場合は特に、ポイント数が多く (100,000 個超)、個々の毛束が互いに無関係に独立しているため、圧縮が特に困難になります。
皮膚のジオメトリなど (筋肉や衣服のデフォーマなど) であれば、通常、ヘアよりはるかに少ないコンポーネント (おそらく 64-128) で対処でき、再構築時の高い精度も維持できます。
この手法を用いる利点
上の方法を使うと、100,000 ポイント分の位置 (浮動小数点 300,000) を学習させずとも、再構築に必要なウェイトを予測するためのモデルさえあればすみます (浮動小数点 64、128、512、1024 あるいは任意の数)。ネットワークを小さく保ったまま、訓練と推論がはるかにスピーディになります。
また、少数のジョイント回転の値を膨大なポイント位置の値のリストにマッピングしようとすると、パフォーマンスに甚大な影響が出てしまいます。
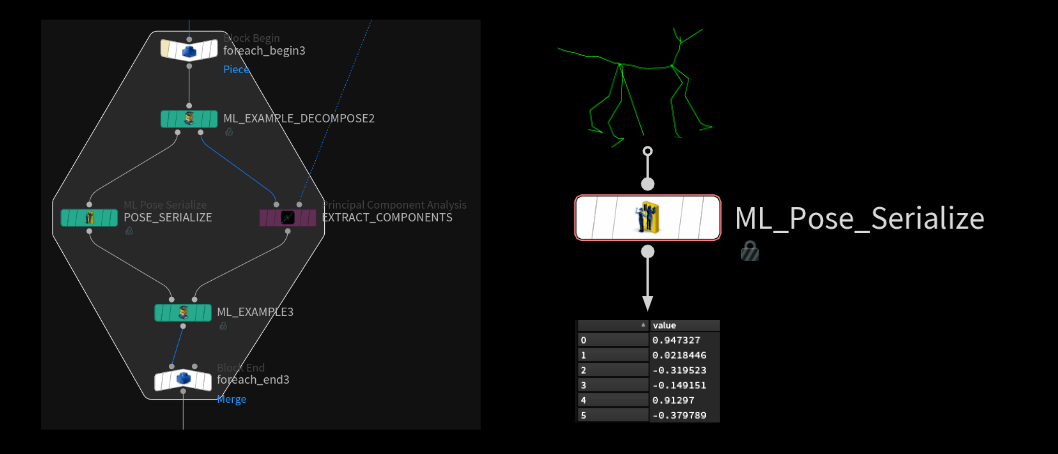
シリアライズ
For Loop の反対側で、新しい ML Pose Serialize SOP を使ってジョイントのトランスフォームをシリアライズします。このノードは、各ジョイントに格納された 3 x 3 のマトリックスを読み込んで -1 から 1 の領域にマッピングし、そのマトリックスを浮動小数点化し、一連の単一ポイント上に格納します。これで、ジョイントの回転情報を表す浮動小数点値の長大なリストができます。これが必要なのは、ニューラルネットワークは、マトリックスが単一の入力であることを好まないためです。-1 から 1 の領域にマッピングするのは、ネットワーク内のアクティベーション機能との相性が良いからです。
データセットのエクスポート
全てのサンプルのポスト処理が済んだら、データセットをディスクに書き出します。ML Example Output SOP で全てのサンプルをまとめてひとつの data_set.raw ファイルに格納し、それをこの後の訓練プロセスで読み込ませます。
訓練
訓練は TOPs 内で完結します。最も大変で大部分の時間を取られるのは、(セットアップや全てのシミュレーションの実行を含む) 準備の工程なので、そこが終われば、後はあまりやることはありません。
ML Regression Train

システム全体の中核をなすのは、見えないところで PyTouch のラッパーとして機能する ML Regression Train TOP です。よく使う訓練用パラメータを全てここで設定できるほか、ユーザが指定した割合を元に、データセットを自動的に訓練データと検証データに振り分けるなどの便利な機能も含まれます。
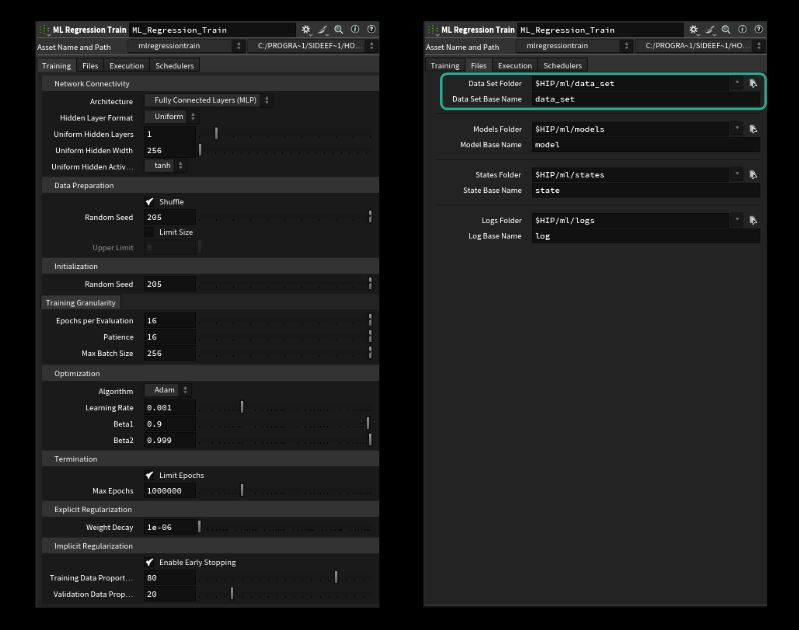
ネットワークの全てのパラメータ (ハイパーパラメータといいます) の制御も可能です。特に重要なものは以下の通りです。
- Uniform Hidden Layers (ネットワークの幅の大きさ)- Uniform Hidden Width (各レイヤーに含まれる「ニューロン」の数)
- Batch Size (平均を取りウェイトを調整する前に見るべきサンプルの数)
- Learning Rate (ゴールまでにモデルが取るステップの大きさ/山から飛び下りるか、慎重に歩いて下るかの違いのようなもの)
Files タブで適切な辞書とデータセット名を指定すれば訓練を開始できますが、デフォルトで適切な状態であるはずです。ファイル名を指定する際、拡張子を付けないよう注意してください。「.raw」を付けると実行されません (H20.5.370 で最終確認)。
ウェッジ化
TOPs 内のノード上に全てのパラメータが揃っているので、そこで最適化をしていきます。これは、ハイパーパラメータチューニングと呼ばれる一般的な手順で、何度か実験を繰り返し、最も性能の良いモデルを返す最適なパラメータの組み合わせを見つけます。先述のパラメータから最適化を始めるのが良いでしょう。ここで使用したグルームの変形サンプルでは、レイヤーの量および各レイヤーのサイズに関する最適化のみを行いました。
推論
あるいは、全てを「逆」に行うこともできます。
推論は、新しい入力にモデルを適用するプロセスのことです。実行するには、訓練の時と全く同じ形で入力が流し込まれる必要があります。
そこで ML Regression Inference SOP を使ってモデルを適用する前に、新しいリグポーズをシリアライズします。この SOP は ONNX Inference SOP の簡易版です。この SOP は、モデルの他に、どの値をどこから読み込む/書き込むかという情報 (ポイントまたはボリューム) を用います。
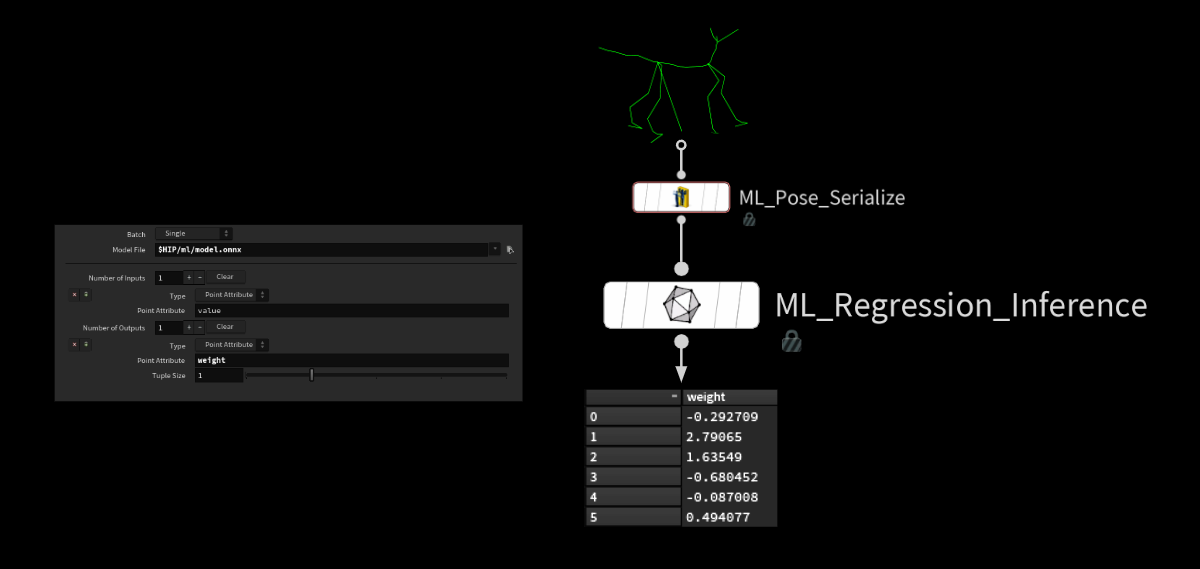
その後、モデルからウェイトのリストが吐き出されます。これを使うと、先ほど保存したサブ空間のコンポーネントに基づいて変位を再構築できます。

このふたつを PCA ノードに流し込み、処理を実行させます。これで、ガイドの変形に必要な変位を得られます。残りの工程はごく簡単です。カーブ上の対応するポイントに各ベクトルを追加することで、予測された変位をガイドに適用します。

そうすると、毛並みが粗く逆毛が立った見た目になりますが、変位のベースとして使用した適切なポーズに変形させると、整った見た目の結果を得られます。


こちらのコマ送りによるプレビューで、元のリニア変形と機械学習による予測との切替を見ることができます。


予測内容のエラーの数値化や視覚化も可能です。画面上の数字は、全てのポイントの差の Root Mean Squared Error (RMSE) を表しています。色は、右側のグラウンドトゥルースと比べた時の局所的なエラーを視覚化したものです。
結果
こちらのスクリーンショットとレンダー画像で、グルーム全体への影響を確認できます。



謝辞
このプロジェクトを支えてくれた、SideFX の優秀なチームの皆さんに感謝します。
全面的なサポート: Fianna Wong
ML ツール開発: Michiel Hagedoorn
オオカミのモデル & グルーム: Lorena E'Vers
CFX 協力: Kai Stavginski & Liesbeth Levick
CREATED BY

コメント
Please log in to leave a comment.