| On this page |
UI/UX ¶
-
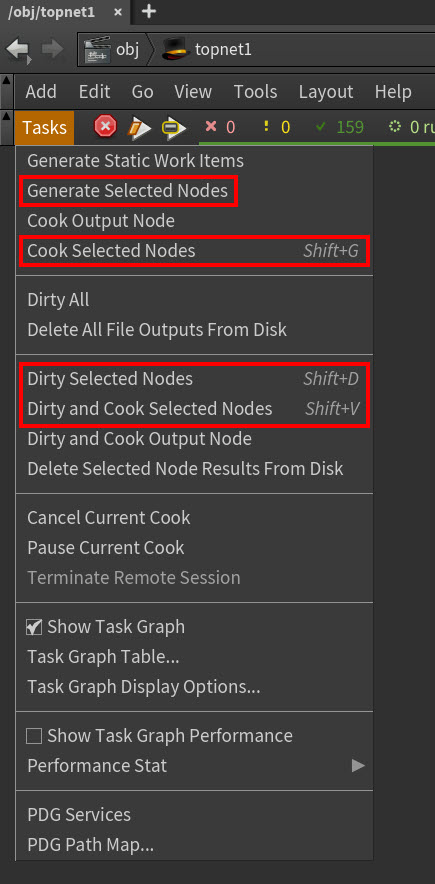
Generate, Cook, or Dirty all the TOP nodes in your current selection at the same time with the Tasks menu options or their associated hotkeys.
-
New unified parameter interface layouts for the
 HQueue Scheduler TOP,
HQueue Scheduler TOP,  Deadline Scheduler TOP, and
Deadline Scheduler TOP, and  Tractor Scheduler TOP farm scheduler nodes.
Tractor Scheduler TOP farm scheduler nodes. -
Improved rendering performance for the TOPs work item dependency graph lines and work item highlighting, especially when a large number of highlighted work items are visible at the same time.
-
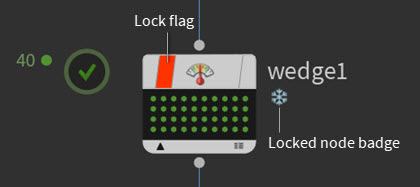
Freeze TOP nodes with the new Lock flag.
-
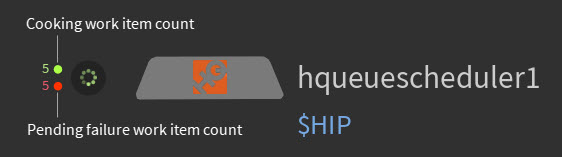
Scheduler TOP nodes now display the number of scheduled work items that are queued, cooking, or pending failures (for work items submitted with farm schedulers).
-
When Farm Schedulers have the Block on Failed Work items parameter turned on, their status icons will now indicate when their cooks are blocked and their nodes are waiting for their failed work items to be resolved. This is useful when you want to directly handle your job failures.

-
Cancel individual PDG work items or all the work items on a node as well as any related work items from the TOPs UI with the new
 menu Cancel options in the Network Editor and Task Graph Table or with the new pdg.WorkItem.cancel() API method.
menu Cancel options in the Network Editor and Task Graph Table or with the new pdg.WorkItem.cancel() API method.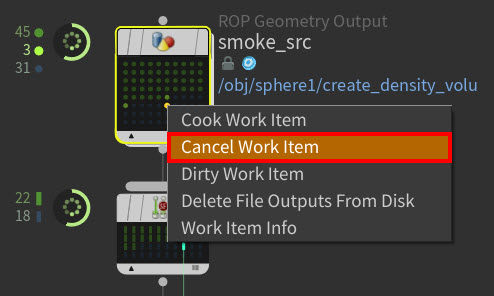
New Cancel Work Item menu option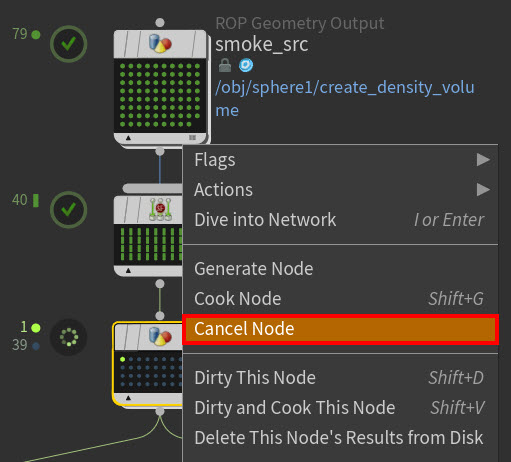
New Cancel Node menu option -
New tasks status bar allows you to inspect the job properties and cook status of individual work items outside of the
/topnetcontext.
-
Manage your jobs more efficiently from the work item info window with the new Reload attributes, Show attribute filter, and Show No Copy attributes buttons.
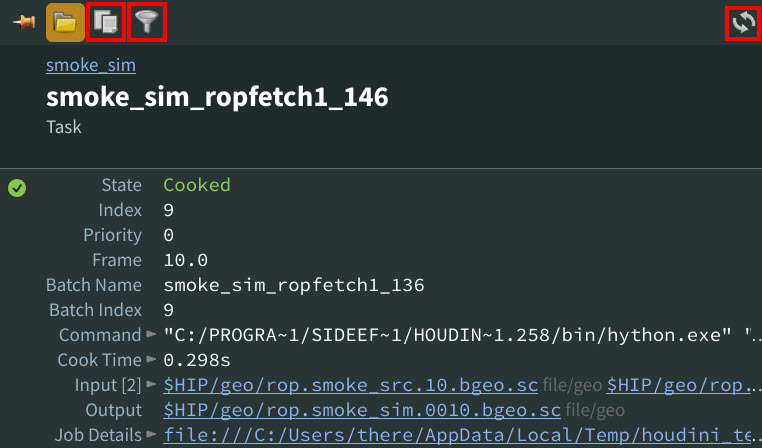
New work item info window buttons -
 Switch TOP,
Switch TOP,  Null TOP, and
Null TOP, and  Output TOP nodes now display the work item dots from their inputs and their corresponding dependency lines.
Output TOP nodes now display the work item dots from their inputs and their corresponding dependency lines.
New Null TOP node with work items and dependencies displayed -
Filter Operator Path parameters by PDG type (Schedulers, Processors, Partitioners, or Mappers) with the new TOP Op Filters in the Edit Parameter Interface window.
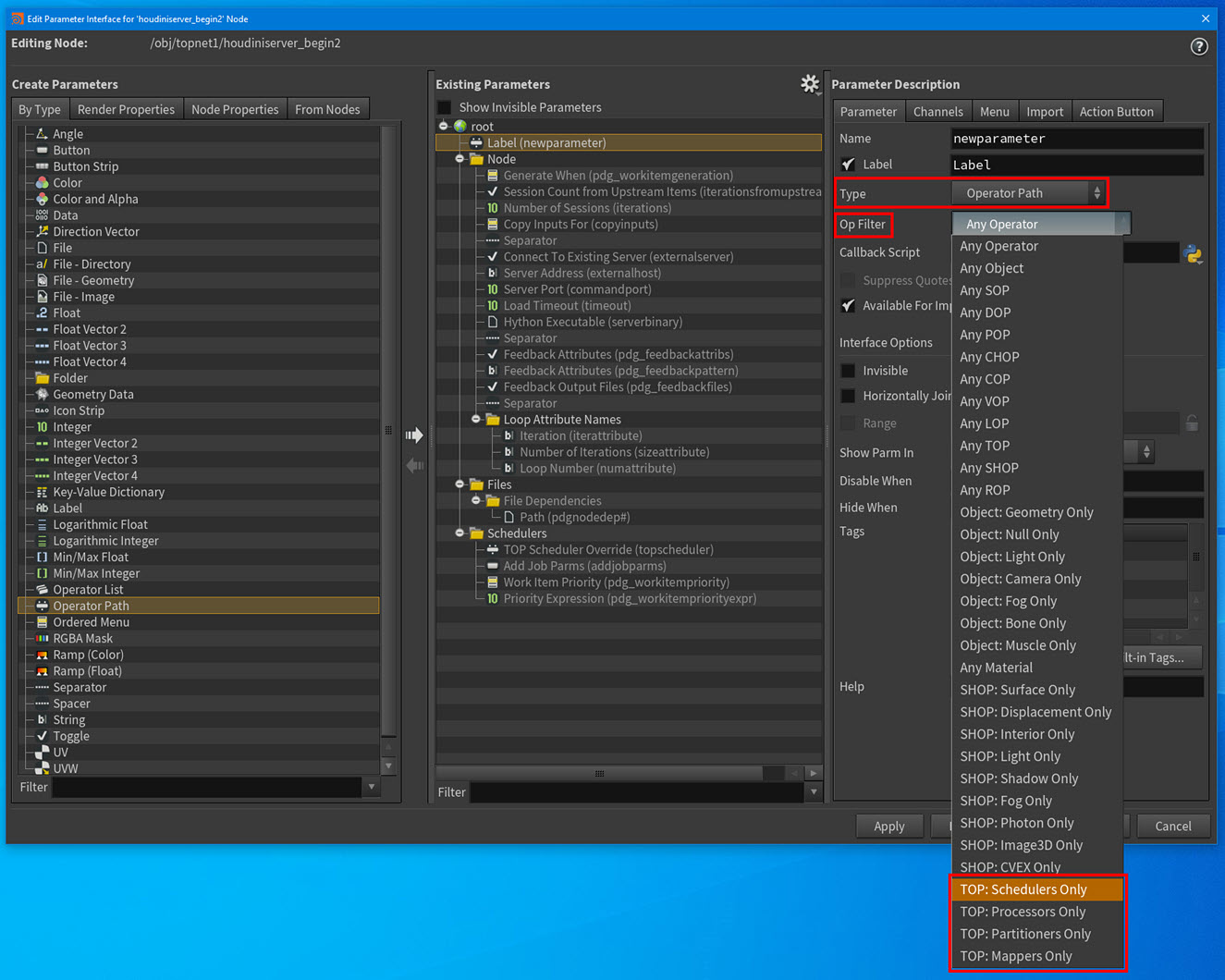
New TOP Op Filters in the Edit Parameter Interface window -
Warnings produced by TOP nodes inside of TOP HDAs no longer automatically propagate up to their assets. If you want a node to promote warnings to its top-level asset, then you need to add it to the Message Nodes list in the asset’s type properties.
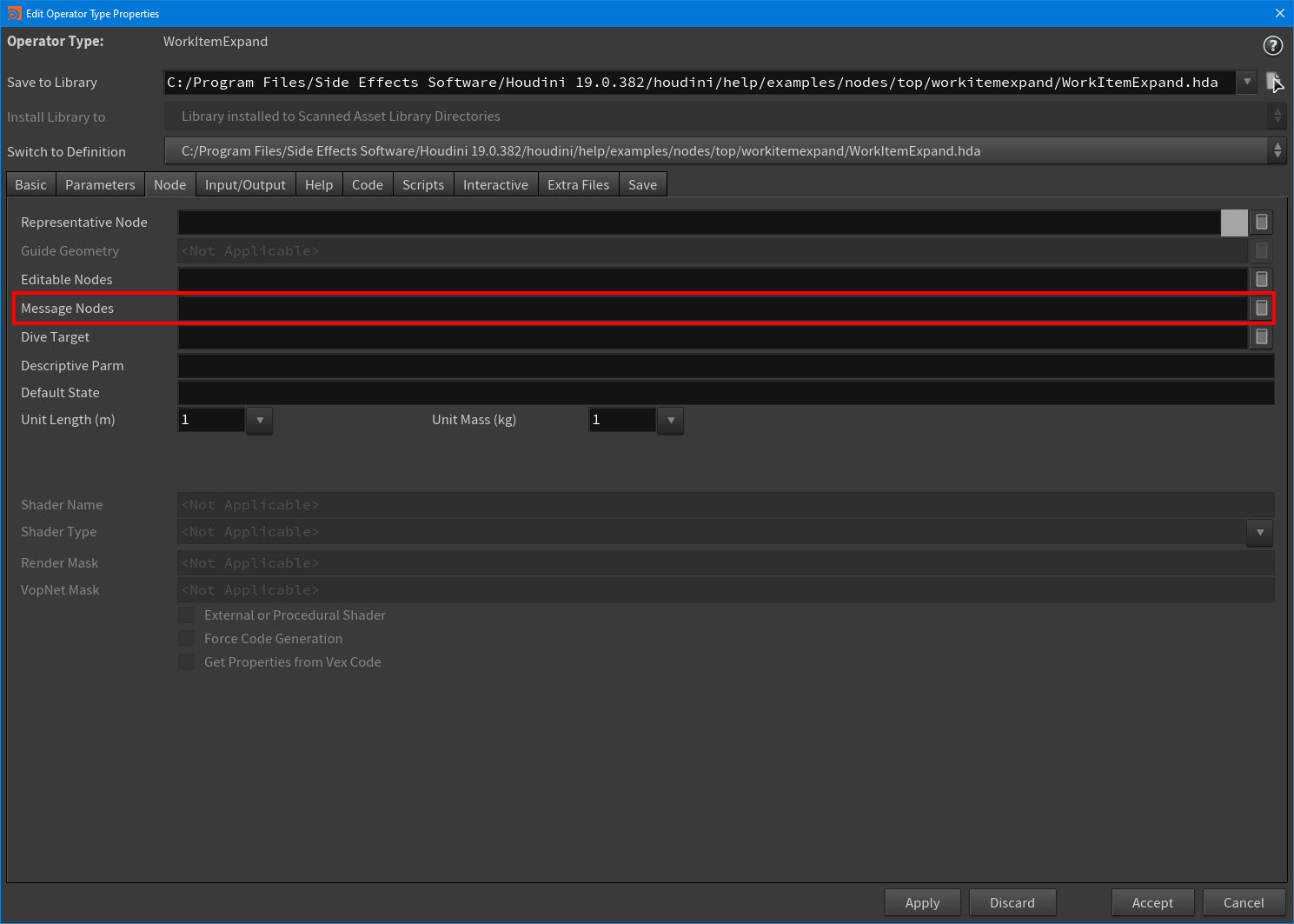
Message Notes field in the Edit Operator Type Properties window -
Terminate a remote Houdini session with the new Terminate Remote Session menu item in the PDG Tasks menu.
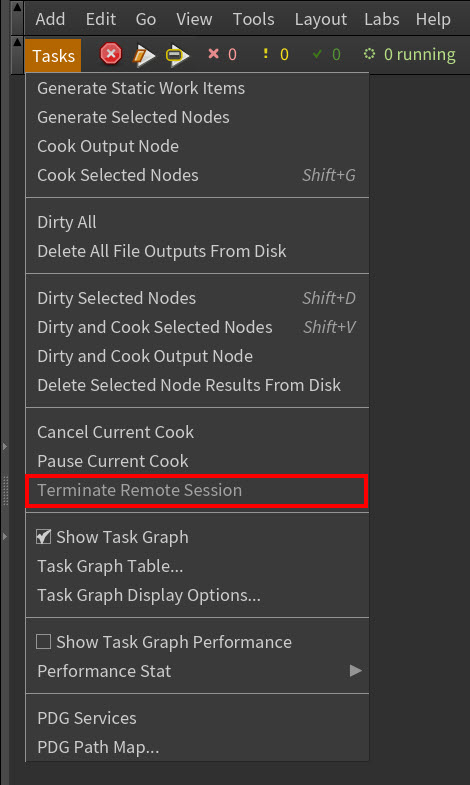
New Terminate Remote Session menu item -
Improved multibyte string support in reported file paths, job script attribute strings, and the TOPs UI.
TOP networks ¶
-
Improved PDG debug logging:
-
All log messages are now time stamped in a consistent format.
-
All log messages now have a PDG prefix to differentiate them from other output.
-
New HOUDINI_PDG_NODE_DEBUG environment variable that enables node debug output.
-
New HOUDINI_PDG_WORK_ITEM_DEBUG environment variable that enables item debug output.
-
-
PDG now always configures nodes to be dynamic or static based on the attributes referenced in their parameters and their internal logic.
-
TOP networks now emit hou.nodeEventType.CustomDataChanged when the work item selection is changed in the UI. You can use this to add a custom HOM event callback that handles the selection of TOP work items.
-
Manually control the work item regeneration behavior of TOP nodes with the new On Node Recook parameter options on the
 TOP Network node or the custom handler installed by the pdg.TypeRegistry() object.
TOP Network node or the custom handler installed by the pdg.TypeRegistry() object. -
Specify a custom time value to use when evaluating parameters in a TOP network that does not have any active work items with the new Custom Time parameter on the
TOP Network node. -
Create one work item for each fetch operation with the new Load Work Items from Fetched Network parameter’s off setting on the
 TOP Fetch node. When this parameter is off, the TOP Fetch TOP node can also be static as it no longer depends on cooked outputs.
TOP Fetch node. When this parameter is off, the TOP Fetch TOP node can also be static as it no longer depends on cooked outputs. -
Specify a custom output directory for a fetched work item data files with the new Custom Output Dir parameter on the
TOP Fetch node. -
TOP Fetch node now runs hython without the
--pdgswitch. This means that it will now never take a PilotPDG license over a Houdini Engine license. -
Whenever the current (selected) work item changes in a
TOP Network, the new hou.nodeEventType.WorkItemSelectionChanged event is now emitted.
PDG services ¶
-
Updated and improved PDG Services panel (formerly known as the PDG Service Manager) interface.
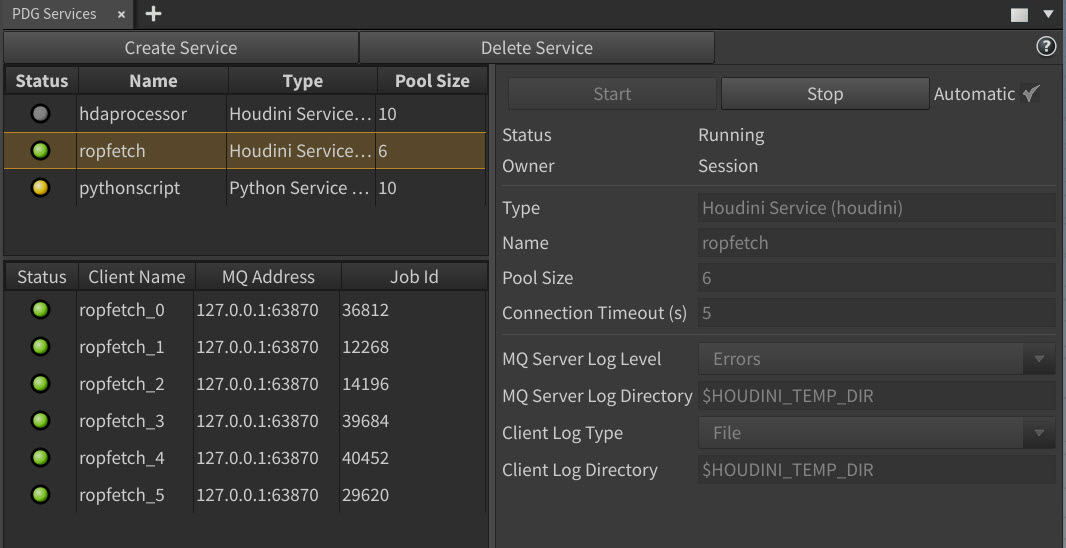
New PDG Services panel 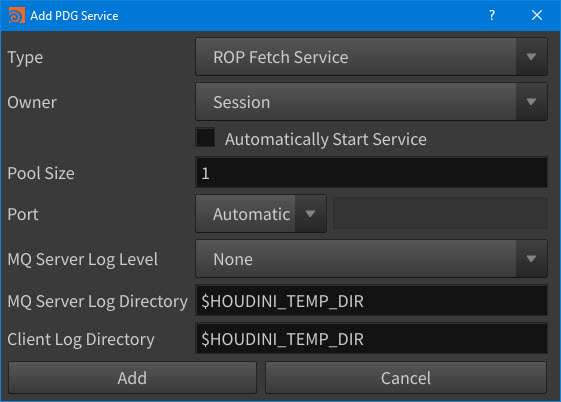
New Add PDG Service window -
PDG Services can now start services in the background. This prevents its panel from blocking your Houdini UI while a service is starting up.
-
PDG now limits the number of service clients being started at once in order to prevent slow downs when starting a service with a very large pool size. This helps ensure that service clients are available to accept work items sooner.
-
PDG Services can now control the log file and logging level of the
mqserverprocess used by the service. -
PDG services are now scheduled using a special internal scheduler that limits the number of concurrent work items based on the pool size of the service.
USD ¶
-
Copy input file paths to work item outputs with the new Add File Path to Outputs parameter on the
 USD Import TOP node.
USD Import TOP node.
Shotgrid ¶
-
The TOP ⇥ Tab menu > Shotgun submenu items are now named ShotGrid.
Geometry & image handling ¶
-
Merge the geometry from upstream partitioned work items on import with the Expand Partitions parameter on the
 Geometry Import TOP node.
Geometry Import TOP node. -
Added the common PDG Add Job Parms parameter to the
 FFmpeg Encode Video TOP node’s interface to give you direct access to the Edit Parameter Interface window for the purpose of quickly adding In-Process Scheduler, Local Scheduler, or HQueue Scheduler parameters to the FFmpeg Encode Video TOP node.
FFmpeg Encode Video TOP node’s interface to give you direct access to the Edit Parameter Interface window for the purpose of quickly adding In-Process Scheduler, Local Scheduler, or HQueue Scheduler parameters to the FFmpeg Encode Video TOP node.
File management & path mapping ¶
-
New custom file transfer handler that allows you to define custom file transfer logic to accommodate your unique submitting/receiving machine, storage system, database, and network set-ups.
-
Copy files to your Scheduler’s working directory (just like the
 File Pattern TOP) with the new Copy File(s) to Working Directory parameter on the File Range TOP node.
File Pattern TOP) with the new Copy File(s) to Working Directory parameter on the File Range TOP node. -
File Pattern TOP node’s
extensionattribute now accepts the full extension of matched files. For example.bgeo.scinstead of just.sc. -
 File Copy TOP node now supports the
File Copy TOP node now supports the FS_Reader. -
 File Compress TOP and
File Compress TOP and  File Decompress TOP nodes can now process large
File Decompress TOP nodes can now process large .zipfiles. -
Improved performance for the
File Decompress TOP node when extracting large numbers of files. -
File Decompress TOP will now try to decompress any input files regardless of their file extension, including
.usdzfiles. -
New Set Output To parameter options on the
 File Remove TOP node now gives you greater control over how the outputs of its work items are determined. This replaces the Set Deleted Files As Outputs parameter.
File Remove TOP node now gives you greater control over how the outputs of its work items are determined. This replaces the Set Deleted Files As Outputs parameter. -
Improved path comparison capabilities when trying to match output files with expected outputs. PDG now tries to resolve duplicate slashes in file paths by normalizing them first. As a result, path comparisons will now succeed in cases where the path is effectively the same but either the reported path or expected path contains redundant slashes.
-
New
*zone allows you to create a path mapping rule that applies to all platforms. This very useful when you want to map a local path through an intermediate symbol or reduce the number of required mapping rules. -
New
MACto PDG file mapping. This allows you to use hybrid Mac OS X/Linux farms without any ambiguity. Mac OS X and Linux machines are now detected asMACandLINUXrespectively instead ofPOSIX. -
New fallback path for path mapping on Mac OS X and Linux.
POSIXwill be tried ifMACorLINUXdo not work on those platforms. This also provides backwards compatibility for path maps that were saved pre-Houdini v18.5.470.
Networks & servers ¶
-
(Mac OS X & Linux) When a Command Chain server times out waiting for a command, it now checks to see if its PDG result server can be reached. This will help you avoid accidentally leaving your servers running after Houdini has been shut down.
-
Copy the output files from each loop iteration onto their corresponding work items at the beginning of the next iteration with the new Feedback Output Files parameter on the
 Block Begin Feedback TOP node and all the
Block Begin Feedback TOP node and all the  Server Begin TOP-type nodes.
Server Begin TOP-type nodes. -
Copy attributes from each loop iteration onto their corresponding work items at the beginning of the next iteration with the new Feedback Attributes parameter on the
Block Begin Feedback TOP node and all the Server Begin TOP-type nodes. -
Make HTTP or HTTPS requests from a TOP graph with the new
 URL Request TOP node. This node provides the same functionality as the
URL Request TOP node. This node provides the same functionality as the  Download File TOP node, but it is able to make REST API calls with an optional payload (set from a work item attribute or file on disk). This node also can save response data, request errors, request status codes, and HTTP headers to disk or an attribute.
Download File TOP node, but it is able to make REST API calls with an optional payload (set from a work item attribute or file on disk). This node also can save response data, request errors, request status codes, and HTTP headers to disk or an attribute. -
Many of the job scripts have been moved to the
$HHP/pdgjobdirectory. This centralizes many of the scripts that can be run on farm blades so that you can now use the directory directly instead of having to copy over scripts from/pdgtemp/scripts. -
Updated MQ Server.
-
mqservernow uses v1.3.1 of thennglibrary. -
New
-roption to disable message batching, which also ensures that work item jobs are evenly distributed between PDG service clients. -
New
-goption to direct all logging to a specified file. -
PDG MQ Task now runs under the
pdgjobcmdwrapper script. This makes it so that you can now easily modify its environment. -
MQ now uses
exit(0)instead ofexit(1)to prevent the whole job from failing when it loses its connection to the submitter machine. You can override this new behavior with$PDG_MQ_FAIL_ON_LOSTCONNECTION=1. Please note that if a real error occurs, then it would appear as an RPC timeout error.
-
Expressions ¶
-
You can now add a prefix before the
@operator in expressions to force the operator to use data from a particular source. The valid prefixes are: G for geometry, C for context options, and P for PDG work item attributes. For example,P@sizewill always resolve to the size work item attribute even if there is an available context option or geometry attribute with the same name. This is very useful when you want to use a mix of context options and PDG attributes in the same TOP network. -
Map a path string to a local zone with the new pdgmappath() expression function. This is the same behavior as the pdg.File.mapPathToLocal() Python function.
-
Query the file tag of a work item’s input or output using a specified index with the new pdginputtag(index) and pdgoutputtag(index) expression functions. You can also use the
@pdg_inputtagshorthand to get the first file’s tag. -
pdgattriblist() expression function now returns the list of attribute names sorted in ascending order.
PDG APIs ¶
-
PDG no longer emits
AddParentandRemoveParentevents. All dependency relationships are now tracked using regular dependencies. Additionally, the pdg.WorkItem.parent property now returns the dependencies from which static work items were generated instead of returningNone. -
Multiple improvements to the pdg.ValuePattern utility for generating value sequences:
-
New
isNumericproperty for checking if the sequence is purely numeric, and whether it has variable step sizes across multiple components. -
Added the
inclusiveoptional argument to all functions. This argument determines whether the end value in ranges should be included. By default, the end values are excluded. -
Updated containsRange() method now returns an approximate bounding range across all numeric components in the pattern.
-
-
pdg.ValuePattern utility now supports the
^character for excluding certain values from a range. -
Custom PDG dirty handlers can now return a boolean to indicate that files were deleted by the handler and to tell PDG that it does not need to delete the files from disk. If the handler does not return a value, then PDG assumes that the files were not deleted by the handler.
-
New pdg.WorkItem.invalidateCache() method for the out-of-process work item API.
-
New runOnMainThread() method for pdg.Scheduler now allows you to run a Python function or callable object on the main thread. This makes it possible to run code from an in-process
 Python Script TOP that is only safe to run on the main thread. For example, like code that opens a Qt message dialog.
Python Script TOP that is only safe to run on the main thread. For example, like code that opens a Qt message dialog. -
New startSubItem() and cookSubItem() methods for pdg.WorkItem now make it possible to mark in-process batch sub-items as started or stopped.
-
New reportResultData() method for
pdgcmdbatches RPC calls from jobs to accommodate cases when there are a very large number of files in a single shot. -
New multiMatch() utility method for pdg.AttributePattern applies a pattern to a list of input names and returns a list of matched strings.
-
New pathToExt() function for pdg.TypeRegistry returns the full extension for a given path including its archive suffix (for example,
bgeo.sc). -
runOnMainThread() function for pdg.Scheduler now preserves the evaluating node path of the caller when running a deferred function. This makes any relative node path references in the deferred function now evaluate correctly. You can also use the new optional
work_itemkeyword argument forrunOnMainThread()to set an active work item for the duration of the deferred function. Any parameter evaluations made will use that work item to resolve@attributesor other PDG work item functions. -
New
node_categoryparameter for pdg.TypeRegistry.registerScheduler() now allows you to specify where the node should be found in the Houdini ⇥ Tab menu. -
New cookOptions() property for pdg.GraphContext now allows you to query back pdg.CookOptions from a graph.
-
New requiresSceneFile() property for pdg.NodeOptions that is passed to the onConfigureNode callback now allows you to indicate if a PDG node depends on the scene file.
-
New saveScene property for pdg.CookOptions now allows you to indicate that your scene file should be saved before starting a cook if any of the nodes in its graph depend on the current scene.
-
Various PDG API methods like addAttrib() and setIntValue() for pdg.WorkItem now take a new
overwriteoptional argument which can be any enum entry from the new pdg.attribOverwrite enumeration. This argument controls what happens when you add an attribute to a work item that already has an attribute with the same name but a different data type. -
New default_match_type optional argument for pdg.AttributePattern configures the default match behavior for terms in a pattern. For example, if pdg.attribMatchType.Both is passed to the pattern constructor, then all terms will behave as if they were expressed as
*term*, unless the terms already has its own explicit*tokens. -
New
clear_outputsoptional argument for the pdg.Scheduler.onWorkItemStartCook() method allows you to clear output files from work items before putting the work items into the Cooking state. This is useful when implementing retries or when dealing with work items that may have failed after adding output files on a previous cook attempt. -
New
active_onlyoptional argument for the pdg.Scheduler.onWorkItemFileResult() method that specifies whether or not the method should apply to items that are already cooked. -
New PDG_BATCH_POLL_DELAY environment variable for the
pdgcmdmodule. This provides a way to change the maximum frequency of batch item polling RPCs. -
New PDG_RELEASE_SLOT_ON_POLL environment variable for the
pdgcmdmodule. This allows schedulers to prevent the acquire/release RPCs if they are not supported. -
PDG job script
top.pyis now namedtopcook.py. -
categoryproperty for pdg.SchedulerType is now named parm_category. This property is used to match the properties (Job Parms) of a specified category. -
inputFilesandoutputFilesproperties for pdg.AttributeInfo are now named InputFiles and OutputFiles respectively. The old properties will continue to work, but they have been deprecated.
Work items ¶
-
IDs for PDG work items are now globally unique to each Houdini session instead of being unique to the PDG graphs that generated them.
-
Time stamps for log messages written to a work item’s internal log buffer now include milliseconds.
-
Your last selected work item and its evaluation are now saved to its
.hipfile. When reloading its.hipfile, any@attribexpressions in its scene will now also evaluate using the attribute values stored on the saved work item. -
Work items on locked nodes are now saved to their
.hipfiles and are loaded when their.hipfiles are reopened. -
Drag & drop a work item’s dot from its TOP node in the Network Editor to a Python shell to quickly copy & paste its work item ID to the shell window. The drop result is formatted as a Python expression that looks up the work item using the PDG API.
-
When evaluating a parameter without an active work item, PDG nodes now default to using the time value that was set when their TOP network began to cook. However, when a parameter is evaluated against a work item, the work item’s frame value is still always used to determine the evaluation time.
-
Batches now wait for the first non-cached frame to be ready to cook rather than just the first frame. This will help to avoid problem situations where the batch cooks from cache even when there is an input frame at the end of the batch that is not cached.
-
PDG work items run by any Scheduler TOP node now save multiple time stamps in addition to their cook duration: a queue time, a schedule time, a cook start time, and a cook end time. You can query this time information from the tracker object returned by the pdg.WorkItem.stats() API method.
-
Assign work items non-unique label strings that are then used to identify the work items in the attribute panel, task bar, and scheduler job names with the new Work Item Label parameter on all nodes that have the Scheduler tab.
-
Work items can now set the pdg.attribFlag.Transfer() flag on file attributes to indicate that they should be copied from their source location to their Scheduler’s remote working directory when the work items cook. This also indicates to PDG that the attribute is a file that needs to be copied to the farm automatically. You can enable this behavior for the
File Pattern TOP, File Range TOP, and  Attribute Create TOP nodes with their new Copy File(s) to Working Directory parameter. This replaces the old File Dependencies multiparm.
Attribute Create TOP nodes with their new Copy File(s) to Working Directory parameter. This replaces the old File Dependencies multiparm. -
Configure your
 Work Item Expand TOP nodes to interpret an integer
attribute as a list of work item IDs and expand those work items into the node with the new Expand as Work Item IDs parameter.
Work Item Expand TOP nodes to interpret an integer
attribute as a list of work item IDs and expand those work items into the node with the new Expand as Work Item IDs parameter. -
Choose when your work items are sorted—after generation or cook—with the new Sort When parameter options on the
 Sort TOP node.
Sort TOP node. -
Ensure that all your work item indices are unique, even when multiple work items have the same sort attribute values, with the new Ensure Unique Work Item Indices parameter on the
Sort TOP node. -
Handle name conflicts by keeping the existing variable values with the new Keep Existing Variable parameter option on the
 Environment Edit TOP node.
Environment Edit TOP node.
Attributes ¶
-
__pdg_attribute prefix is now reserved for only internally defined attributes created by PDG, like the input/output file lists. TOP nodes like the Attribute Create TOP or  Wedge TOP will now treat attribute names that begin with
Wedge TOP will now treat attribute names that begin with __pdg_as invalid. -
PDG integer attributes are now stored as 64-bit values instead of 32-bit.
-
@attrib:<padding>syntax now rounds floating-point values to the nearest integer when a padding value is specified. This behavior now matches that of the padzero() HScript function that performs the same operation. -
Attribute TOP nodes that have multiparms now have a new on/off checkbox next to each multiparm entry. You can use this checkbox to conditionally set an attribute with an expression or quickly turn on/off attribute entries when debugging your nodes.
-
Handle name conflicts by keeping the existing attribute or variable values with the new Keep Existing Attribute parameter option on the
Attribute Create TOP and  Attribute Array TOP nodes.
Attribute Array TOP nodes. -
Make work items copy input files to their output file lists with the new Copy Inputs to Outputs
 Attribute Delete TOP node.
Attribute Delete TOP node. -
Indicate that an attribute should be copied between dependent work items located on the same node before the work items cook with the new pdg.attribFlag.Dependent() attribute flag.
Schedulers ¶
-
Transfer any Scheduler TOP node’s work item data via RPC or save the data to disk as a
.jsonfile with the new Load Item Data From parameter options. The RPC Message option is especially useful when your local and remote machines do not share a file system. -
Compress any Scheduler TOP node’s work item data
.jsonfiles when writing them to disk with the new Compress Work Item Data parameter. -
Suspend the cook on most Scheduler TOP nodes until all their failed work items can be retried with the new Block on Failed Work Items parameter.
-
Validate the output files of any Scheduler TOP node and automatically dirty and recook their work items if output files are missing with the new Validate Output Files parameter. You can turn on/off Validate Output Files per scheduler instance. For example, you can turn it off for your farm schedulers to block NFS access, and then turn it on for your local scheduler.
-
Check on disk for any work item outputs that need to be validated and then automatically add them as valid outputs with the new Check Expected Outputs on Disk parameter on any Scheduler TOP node.
-
Custom PDG Schedulers now support the scheduling of in-process work items and the running of work item in-process cooks when they call the self.setAcceptInProcess(..) and
self.cookWorkItem(..)API methods from the onStartCook scheduler callback. -
Specify whether to terminate or keep jobs open after they finish their cooks with the new When Finished parameters on the
HQueue Scheduler TOP, Deadline Scheduler TOP, and Tractor Scheduler TOP farm scheduler nodes. -
Create a remote graph automatically when submitting a graph as a job with the new Auto Connect parameter on the
HQueue Scheduler TOP, Deadline Scheduler TOP, and Tractor Scheduler TOP farm scheduler nodes. -
Remove environment variables from your task environment that were copied from the local process environment with the new Unset Variables parameter on the
 Local Scheduler TOP, HQueue Scheduler TOP, Deadline Scheduler TOP, and Tractor Scheduler TOP nodes.
Local Scheduler TOP, HQueue Scheduler TOP, Deadline Scheduler TOP, and Tractor Scheduler TOP nodes. -
Delay a job from starting until a specific amount of memory is available with the new Minimum Available Memory parameters on the
Local Scheduler TOP node. -
Control the maximum run time (in seconds) that work items can run with the new Maximum Run Time parameter on the
Local Scheduler TOP node. If a work item takes longer to cook than the time limit, the work item’s process is automatically terminated by the Scheduler. For the work items that time out, you can also set their statuses with the On Task Timeout parameter. -
Change how in-process work items are handled when they encounter errors while cooking with the new Tasks parameters on the
In Process Scheduler TOP node. These parameters allow you to report task failures or retry the failed jobs a specific number of times. -
The Load Path Map button in the
HQueue Scheduler TOP node’s parameter settings now automatically adds network drives to UNC path mapping. -
Save a task graph
.pyfile for submitted jobs once their cooks complete with the new Save Task Graph File parameter on the HQueue Scheduler TOP node. -
Connect to a persistent MQ server with the new Connect parameter option on the
HQueue Scheduler TOP node. This is useful when you want multiple HQueue Scheduler TOP nodes in your network to re-use and connect to the same MQ server service. -
Deadline Scheduler TOP node now supports PDG Path Mapping and preserves the HOUDINI_PATH environment variable when it set in the task environment. This is made possible by the new Path Mapping and Path Map Zone parameters.
-
Delay a job from starting until certain other jobs have completed with the new After Jobs parameter on the
Tractor Scheduler TOP node. -
Apply custom prefixes to the names of your tasks with the new Task Title parameter on the
Tractor Scheduler TOP node. -
Automatically kill tasks that run past a set time limit with the new Maximum Run Time parameter on the
Tractor Scheduler TOP node. -
Specify how long to wait before exiting a successful job with the new Post Success Wait parameter on the
Tractor Scheduler TOP node. This allows Tractor to spool the next high-priority job before it assigns the blade to a different job. -
View in-progress cook results using an external application with the new Preview Launch parameter on the
Tractor Scheduler TOP node. -
Tractor Scheduler TOP node Submit As Job tasks now have a suffix that is the hash value of their associated work items. This allows the Tractor wrangler to retry Submit As Job tasks instead of spooling duplicates.
-
New environment variables for the
Tractor Scheduler TOP node: PDG_TRACTOR_USEKEEPALIVE, PDG_TRACTOR_PASSWORD_FILE, and PDG_TR_SPOOLER_DELGATE.
Processors ¶
-
Processor TOP nodes now define their Generate When and Cache Mode menus with menu scripts instead of directly in the parameter interface. Custom TOP assets that expose the same parameters in their interfaces can also use the menu scripts.
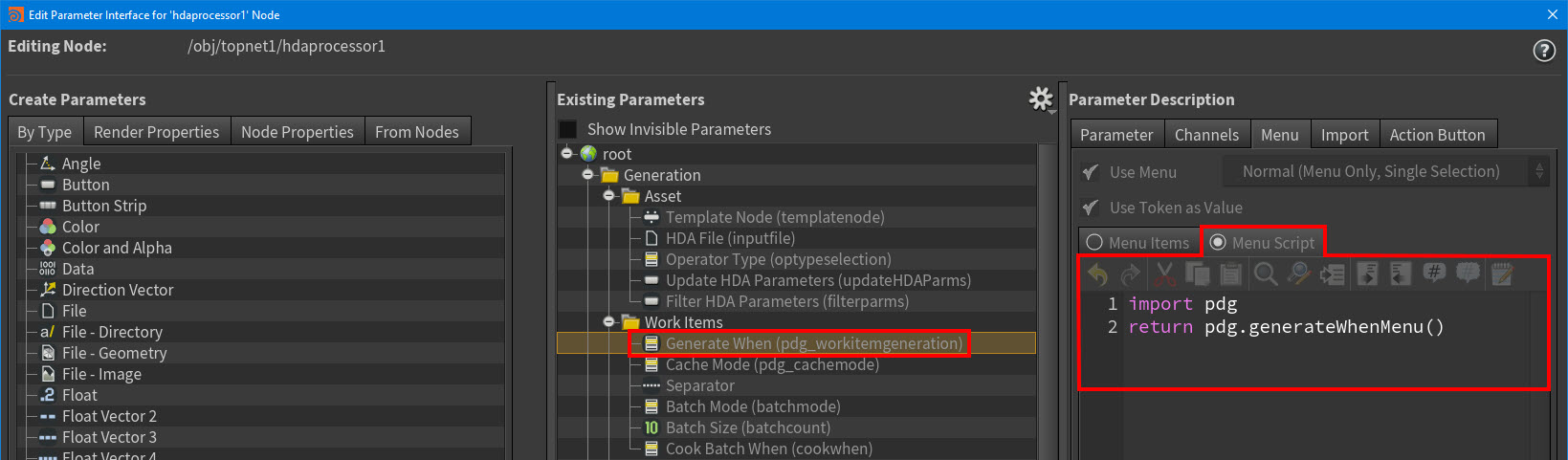
New Generate When menu settings in the Edit Parameter Interface window. 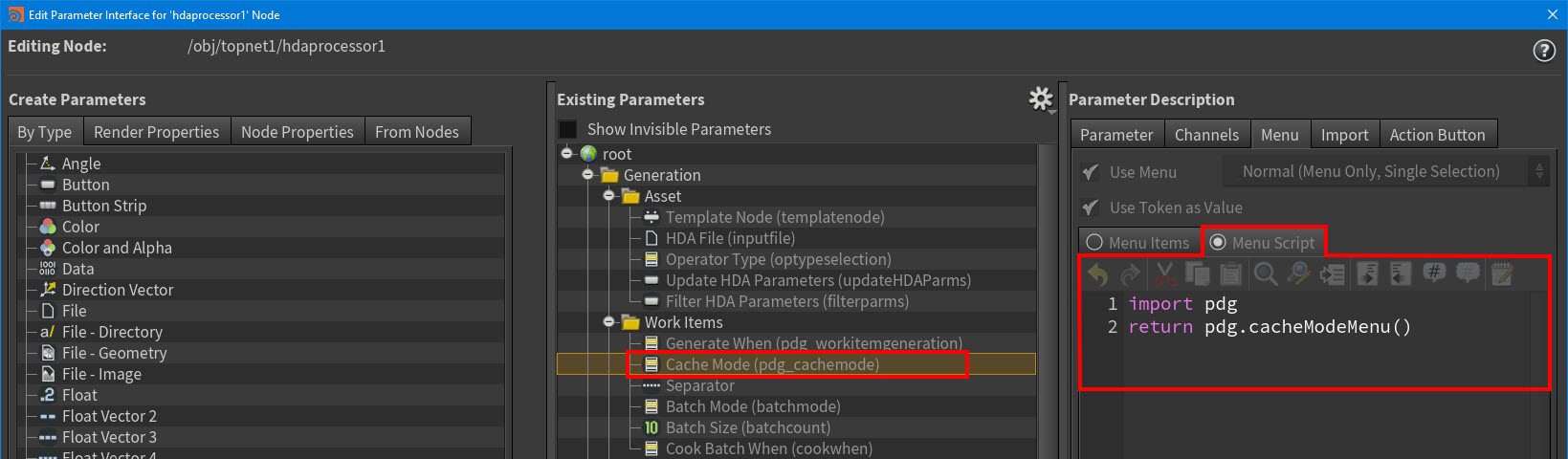
New Cache Mode menu settings in the Edit Parameter Interface window. -
Processor TOP nodes can now ignore any invalidation caused by upstream work item changes and only check output files for their own work items with the new Cache Mode parameter > Automatic (Ignore Upstream) setting.
-
Generate work items from nodes in your scene that match a specific pattern with the new
 Node Pattern TOP node. With this node you can create a single work item with all matching node paths stored as a string array or create one work item per matched node. This node uses the same pattern syntax as the Find Node window in the Network Editor.
Node Pattern TOP node. With this node you can create a single work item with all matching node paths stored as a string array or create one work item per matched node. This node uses the same pattern syntax as the Find Node window in the Network Editor. -
 Generic Generator TOP node now supports caching (even when using Command Builder) with the new Cache Mode parameter options.
Generic Generator TOP node now supports caching (even when using Command Builder) with the new Cache Mode parameter options. -
Generic Generator TOP node’s Command Builder now supports arguments that don’t have a value as well as the conditional enabling of arguments using expressions.
-
When using a
Local Scheduler, you can now run the work item command in the system shell with the new Run Command in System Shell parameter on the Generic Generator TOP node. -
Ensure that the index values for your generated work items are contiguous and range from 0 to
num_items-1even when your input work item list has gaps or the Item Count is set to a variable size with the new Flatten Work Item Indices parameter on the Generic Generator TOP nodes. -
Specify explicit work item output files with the new Expected Outputs parameters on the
Generic Generator TOP node. -
Wedge TOP node now adds the wedgecount and wedgetotal attributes to all the work items it generates.
-
Generate frame ranges from a custom pdg.ValuePattern() with the new Specify Range As parameter > Custom Range setting on the
 Range Generate TOP node. This allows you to specify a disjointed range or one that consists of numeric values and ranges.
Range Generate TOP node. This allows you to specify a disjointed range or one that consists of numeric values and ranges. -
 HDA Processor TOP nodes now export HIP and JOB environment variables to the jobs they spawn. This makes the HDA configuration process much more seamless as the environment of the processes that cook the HDA now have the same HIP and JOB environment variable values as the Houdini processes that cook the PDG graph.
HDA Processor TOP nodes now export HIP and JOB environment variables to the jobs they spawn. This makes the HDA configuration process much more seamless as the environment of the processes that cook the HDA now have the same HIP and JOB environment variable values as the Houdini processes that cook the PDG graph. -
Configure how HDA Parameter attributes are added to your work items—manually or automatically—with the new Add HDA Parameters parameter on the
HDA Processor TOP node. -
Create work items that require access to the current scene file with the new Requires Scene File node option parameter on the
Python Processor TOP node. -
Disable the expansion of
$variablesin the string attributes for work items with the new Expand Variables in String Attributes parameter on the Python Script TOP node. -
Copy input files to the output file list when the Python script does not add any outputs with the new If Script Doesn’t Add Outputs parameter on the
Python Script TOP node.
Partitioners ¶
-
Mapper TOP nodes are now deprecated. Please use Partitioner TOP nodes in their place.
-
All Partitioners in feedback loops can now put work items into partitions from different iterations. Any partition created this way will be associated with the largest iteration number from the work items in that partition.
-
Partition work items based on their iteration and loop number in a feedback loop block with the new
 Partition by Iteration TOP node. You can also use this node to combine work items from multiple iterations into a single partition, including work items that are in different loop levels and work items that are completely outside of the loop.
Partition by Iteration TOP node. You can also use this node to combine work items from multiple iterations into a single partition, including work items that are in different loop levels and work items that are completely outside of the loop. -
Control what frame value is copied to a partition from its work items with the new Set Partition Frame To parameter on most Partitioner TOP nodes.
-
Easily recover lists of partitioned work items downstream of a Partitioner TOP node with the new Store Items to Attrib parameter on most Partitioner TOP nodes. This parameter allows you to write the IDs of partitioned work items to an attribute.
-
Specify a default value for work items that are missing the split attribute with the new Default Value parameter on most Partitioner TOP nodes.
-
Specify which frames (Individual Frames or Frame Ranges) the partitions are created for with the new Create Partitions For parameter on the
 Partition By Frames TOP.
Partition By Frames TOP. -
Specify how work items should be ordered in their partitions with the new Order By parameter on the
 Partition by Range TOP node.
Partition by Range TOP node. -
Always group work items that have the same sorting key with the new Consolidate Work Items by Key parameter on the on the
Partition by Range TOP node. -
Reset the indices of the work items in your partitions when their Range Types are either First/Last Value or First/Middle/Last Value with the new Reset Work Item Indices parameter on the
Partition by Range TOP node. -
Python Partitioner TOP nodes that are configured to split by attribute can now determine on their own what happens to their input work items when they are missing the specified Split by Attribute with the new Handle Work Item in Python Code parameter option.
-
Sort work items flagged as
requiredto the beginning of your partitions with the new Prioritize Required Work Items parameter on the Python Partitioner TOP node. -
Use a custom box or sphere bounding region instead of input geometry and specify which input elements are compared against or excluded from the bounding region with the new Bounds Source parameter options on the
 Partition by Bounds TOP node.
Partition by Bounds TOP node. -
Change how the orientation and axis alignment of input bounding geometry is interpreted with the new Use Geometry As parameter on the
Partition by Bounds TOP node. -
Specify additional inputs on the
 Merge TOP node with the new Extra Inputs multiparm. This new behavior is similar to how the
Merge TOP node with the new Extra Inputs multiparm. This new behavior is similar to how the  Object Merge SOP node handles its extra inputs.
Object Merge SOP node handles its extra inputs.
ROP workflows ¶
-
New tools for easier debugging and performance monitoring of the
 ROP Fetch TOP node and related subnets.
ROP Fetch TOP node and related subnets.-
Turn on the Performance Monitor for your ROP Fetch TOP nodes with the new Enable Performance Monitor Logging parameter. This will allow you to print performance information to the work item log.
-
Write Houdini performance monitor data and scene states to disk with the new Performance File parameter.
-
Save debug
.hipfiles to disk with the new Save Debug .hip File parameter. -
Attach your performance monitor output files and debug
.hipfiles to work item outputs with the new Report Debug Files as Outputs parameter.
-
-
Create work items that cook an embedded Karma ROP with the new
 ROP Karma Render TOP node. You can access both Karma LOP and ROP Fetch TOP parameters from this node’s interface.
ROP Karma Render TOP node. You can access both Karma LOP and ROP Fetch TOP parameters from this node’s interface. -
Automatically assign
frameandrangevalues when generating batches when your input work items are missing frame values with the new Automatically Set Missing Frames parameter on the ROP Fetch TOP node and related subnets. The work items are assigned an incrementing frame and a range of 1 to num_items. -
Automatically configure the
ROP Fetch TOP node based on whether or not it has any inputs with the new Automatic option for the Evaluate Using parameter. If your ROP Fetch TOP node has inputs, it will generate one frame of work for each input. And if it does not have inputs, it will generate work items for the full frame range. -
Specify a custom list of output files for the
ROP Fetch TOP node with the new Custom Path List options for the Output Paths From parameter. This is useful in instances when PDG cannot determine the output file paths from the ROP node itself. These file paths are used to add cache paths to the work items created by the node, and they are validated on disk when a work item is done cooking. -
Output Parm Name parameter field on the
ROP Fetch TOP node now accepts the following:-
Multiparm instances. For example, like
outputfile#. -
A space-separate list of parameter names. This now makes it possible to cook a chain of ROPs in which some of the nodes have non-standard output parameter names.
-
-
Customize the name of the execute button parameter that is used when the
ROP Fetch TOP node cooks a non-ROP node with the new Execute Parm Name parameter. -
Specify how a chain of ROPs or a ROP network should be cooked with the new ROP Cook Order parameter on the
ROP Fetch TOP node. -
ROP Fetch TOP node’s sim tracker worker items and their processes are now created the same way as any other work item, and they now also appear as regular farm jobs when using the HQueue, Tractor, or Deadline Schedulers.
-
ROP Fetch TOP now adds an
ifdoutputattribute to the IFDs it generates. This attribute can then be used by the Render IFD TOP node to create expected output paths and cook from its cache.
Render IFD TOP node to create expected output paths and cook from its cache. -
Specify a custom tracker and web port when running a distributed simulation with the new Custom Tracker Port and Custom Web Port parameters on the
ROP Fetch TOP and  ROP Geometry TOP nodes.
ROP Geometry TOP nodes. -
ROP Geometry TOP node and
 ROP Composite TOP node now have the Cook Frames as Single Work Item parameter which allows you to cook all their frames as a single work item.
ROP Composite TOP node now have the Cook Frames as Single Work Item parameter which allows you to cook all their frames as a single work item. -
Now by default, only one Mantra job will run per machine when you schedule your
ROP Mantra Render TOP jobs with the HQueue Scheduler. This will prevent your CPU resources from being oversubscribed.