| On this page | |
| Since | 17.5 |
Overview ¶
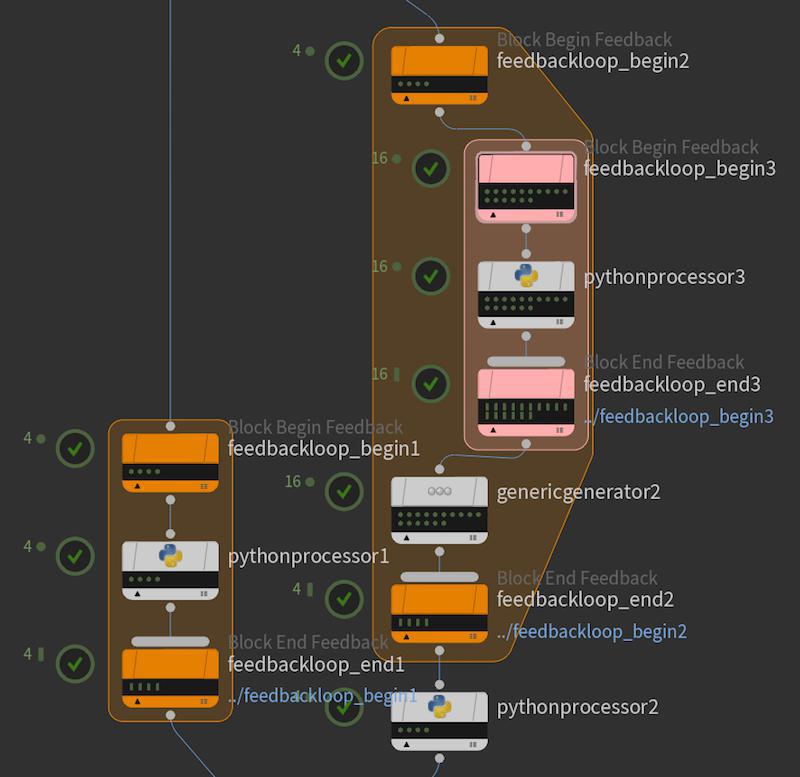
A TOPs Feedback Loop block lets you run a sequence of serially executed steps for multiple iterations.
A TOP network already behaves like a parallel loop: it runs as many work items at the same time as possible based on the scheduler settings. So there’s no need for a typical loop construct since “repeating the same action with different inputs” is how the network works.
Sometimes, you may want to run a series of steps serially rather than in parallel, and use the output of previous work items as input for subsequent work items. For simple simulations this is already handled by the ![]() ROP Fetch node, which is able to create batches that run as a single job, one frame at a time.
ROP Fetch node, which is able to create batches that run as a single job, one frame at a time.
For more complicated use cases, such as looping that spans multiple nodes, or where the size of the feedback loop isn’t fully known, you can use a feedback loop.
In a feedback loop block, the network runs the work items node by node, with later work items depending on the previous work items, forcing them to execute serially. Then when all work in an iteration is done, if the block specifies more than one iteration, it loops back to the start and executes the next loop.
Tip
Depending on the settings, a feedback loop block can also run multiple serial loops in parallel.
For example, you perform an RBD simulation where a jar is being filled with marbles, one handful at a time. The entire process could be run as a single simulation, however marbles at the bottom of the jar might become unstable and the numbered of simulated objects would keep growing. One way to manage this is to run the RBD simulation for the first handful of marbles and use its results as a static object in the second simulation. The result of the second sim and first sim combined would be static objects in the third sim, and so on. You can do this in TOPs using a feedback loop with a ROP Geometry in the loop block.
(Feedback loops are also used to implement Service Blocks, where the work itemes are assign to a a service process and execute sequentially in-depth first order).
Tips and notes ¶
-
You can use any processor node in a feedback loop. Currently, you cannot use a dynamic partitioner inside a feedback loop. You can use static partitioners, if the partitions only contain work items from the same loop iteration. If work items from different iterations are somehow partitioned together, the partition node reports an error.
-
You should color the start and end nodes of a block the same to make their relationship clear. The default nodes put down by the For-Loop tool are colored orange, but you can change the node colors. This is useful to distinguish nested loops.
The border around the block takes on the color of the end node.
-
The begin node is a processor that generates loop iteration work items.
-
Each work item depends on the previous item from the same loop, and has attributes to identify the iteration and loop number.
The feedback end node is a partitioner which partitions work items based on the loop iteration they're associated with. This is useful because the nodes in the feedback loop are free to fan out into as many additional items as needed, and the partitioner will collect them. The second loop iteration item in the begin node depends on the partition for the first loop iteration, and so on. If the loop begin is generating work items dynamically, the feedback end node must be set to use dynamic partitioning.
-
You can wire a node from outside the feedback block into a node inside the block that has multiple inputs.
Tip
The $HH/help/files/pdg_examples/top_feedbackhda and $HH/help/files/pdg_examples/top_feedbacksim examples show how you can use this node to cook geometry that is based on the output of a previous iteration.
TOP Attributes ¶
The names of these attributes can be configured using parameters on the node.
|
|
[int] |
The loop iteration number. This attribute can be an array of values when using nested feedback loops, since the iteration number at each level is preserved. The loop iteration value for the outer most loop is stored in |
|
|
int |
Tracks which loop the work item is associated with. This attribute is
relevant when generating multiple independent loops in the same feedback
begin node, for example by driving the feedback begin node with a
|
|
|
int |
The total number of iterations in the current loop. |
Tip
If you have nested loops, you may want to give the loopiter/loopsize attributes different custom names at each nested level to avoid having to deal with arrays.
Parameters ¶
Generate When
Determines when this node will generate work items. You should generally leave this set to “Automatic” unless you know the node requires a specific generation mode, or that the work items need to be generated dynamically.
All Upstream Items are Generated
This node will generate work items once all of the input nodes have generated their work items.
All Upstream Items are Cooked
This node will generate work items once all of the input nodes have cooked their work items.
Each Upstream Item is Cooked
This node will generate work items each time a work item in an input node is cooked.
Automatic
The generation mode is selected based on the generation mode of the input nodes. If any of the input nodes are generating work items when their inputs cook, this node will be set to Each Upstream Item is Cooked. Otherwise, it will be set to All Upstream Items are Generated.
Iterations from Upstream Items
Set the number of iterations based on the number of incoming static work items, instead of the Iterations parameter.
Iterations
If the Begin node has upstream items, the loop runs this number of times for each incoming item.
Copy Inputs For
Determines how input files are copied onto loop items. By default, upstream files are copied onto all input files. However, it is also possible to only copy input files onto the first iteration or none of the loop iterations.
No Iterations
Upstream input files are not copied to the outputs of any loop iteration items.
First Iteration
Upstream input files are copied to the output file list for only the first loop iteration
All Iterations
Upstream input files are copied to the output file list of all iterations.
Cook Loops Sequentially
When on, loops created by this node cook to completion one at a time. When off, independent loops are able to cook in parallel.
Feedback Attributes
When on, the specified attributes are copied from the end of each iteration onto the corresponding work item at the beginning of the next iteration. This occurs immediately before the starting work item for the next iteration cooks.
Tip
The attribute(s) to feedback can be specified as a space-separated list or by using the attribute pattern syntax. For more information on how to write attribute patterns, see Attribute Pattern Syntax.
Feedback Output Files
When on, the output files from each iteration are copied onto the corresponding work item at the beginning of the next loop iteration. The files are added as outputs of that work item, which makes them available as inputs to work items inside the loop.
These parameters can be used to customize the names of the work item attributes created by this node.
Iteration
The name of the attribute containing the work item’s iteration number.
Number of Iterations
The name of the attribute containing the total iteration count.
Loop Number
The name of the attribute that stores the loop number.
Examples ¶
FeedbackBegin Example for Block Begin Feedback TOP node
This example demonstrates how to create a feedback loop.
FeedbackModes Example for Block Begin Feedback TOP node
This example demonstrates the different ways upstream files are copied onto feedback begin loop iterations.
| See also |