| On this page |
UI/UX ¶
-
Global attributes now appear in the
 information panel for
information panel for  TOP Network nodes in any context. The global attributes also use the same color scheme—pink for Strings, green for Integers, orange for Floats, and so on—as regular work item-level attributes.
TOP Network nodes in any context. The global attributes also use the same color scheme—pink for Strings, green for Integers, orange for Floats, and so on—as regular work item-level attributes.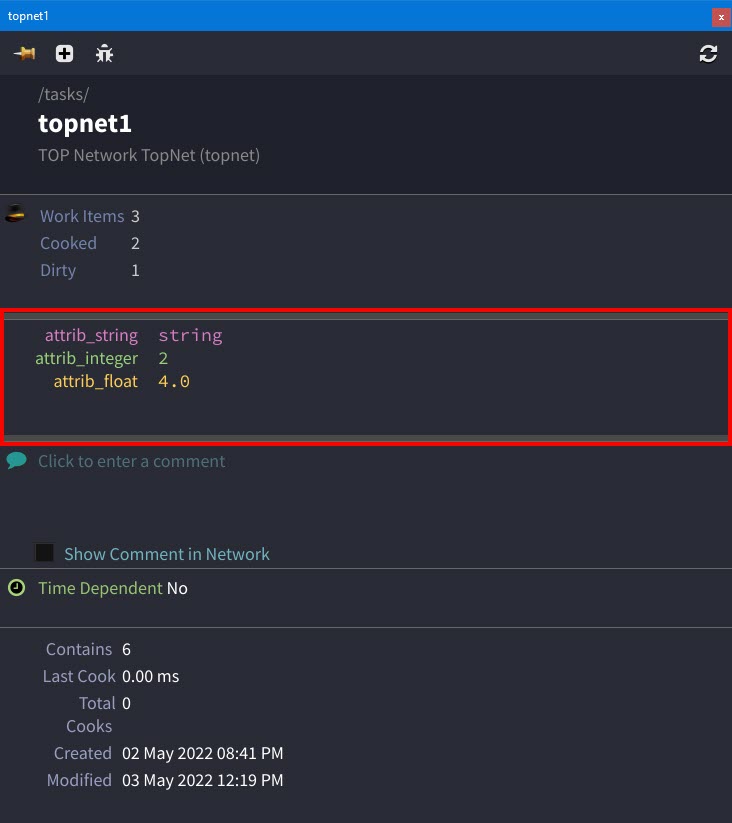
-
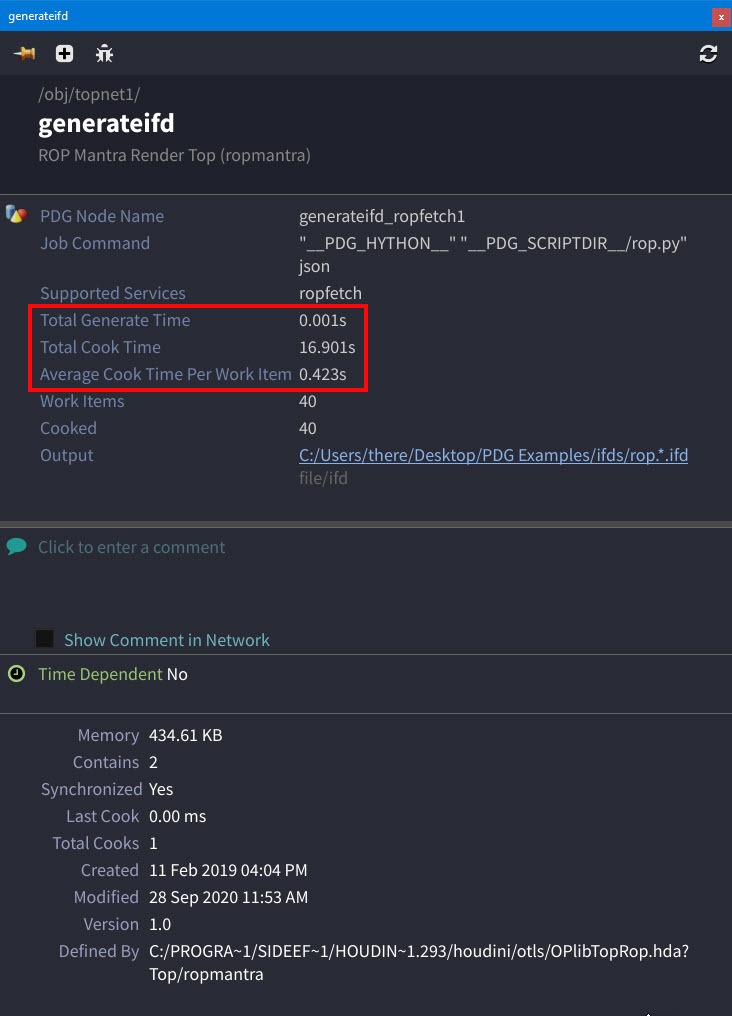
The Total Generate Time, Total Cook Time, and Average Cook Time Per Work Item for a given node now appears in the MMB information panel for all TOP nodes.
-
Job script command line information and compatible services for a given node now appear in the
information panel for all Processor TOP nodes.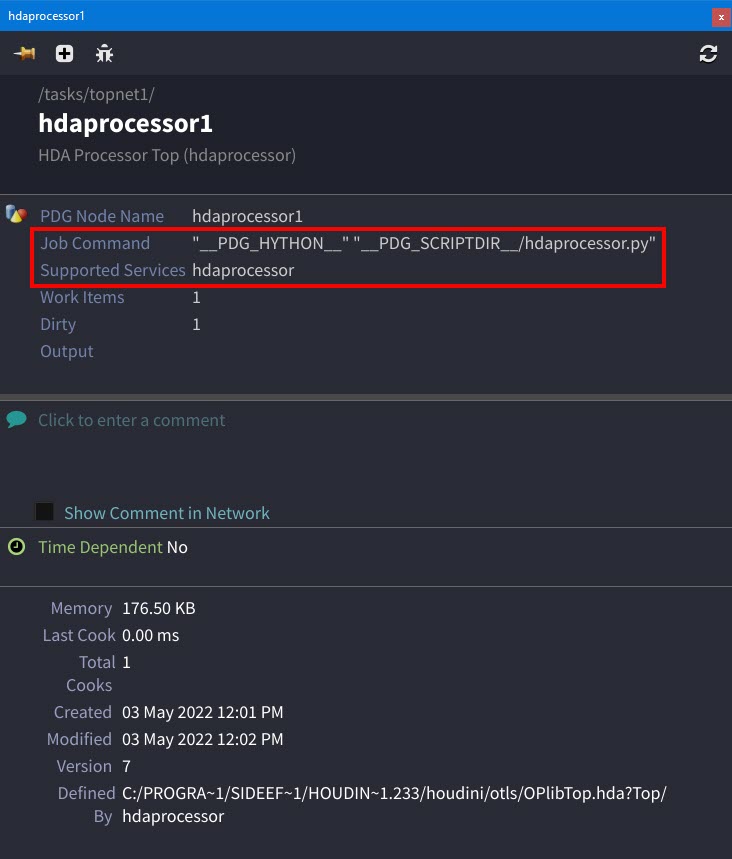
-
Select which output files to remove from disk for any TOP node with the Delete This Node’s Output Files from Disk
 -menu option’s new Make Selection window.
-menu option’s new Make Selection window.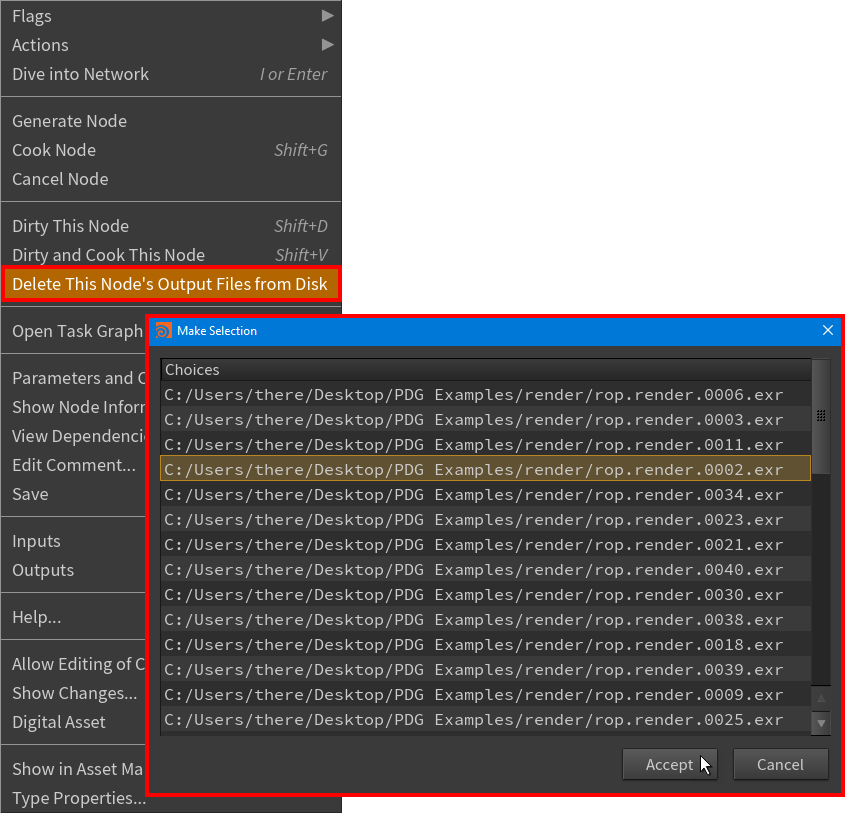
Delete This Node’s Output Files from Disk right-click menu item > Make Selection window -
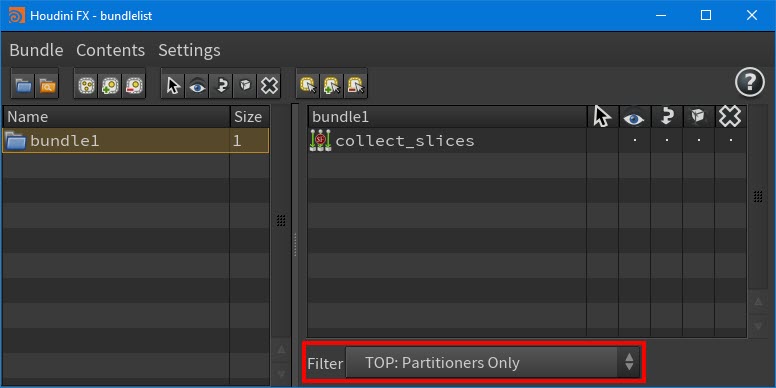
Filter your bundle nodes by PDG node type (like by Schedulers, Processors, or Partitioners) with the new TOP filters located in the Bundle List pane > Filter drop-down list.
-
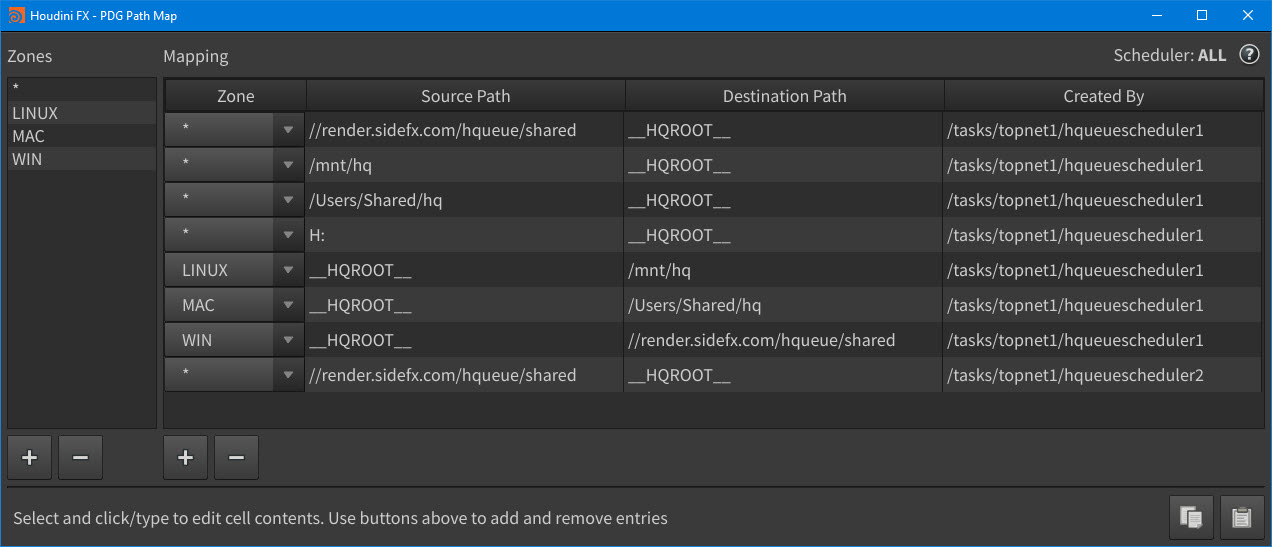
Add custom zones for your PDG path maps and view which schedulers created each mapping with the improved PDG Path Map pane.
TOP networks ¶
-
Specify a default work item label for all the tasks in a TOP network that have the default label setting with the new Default Item Label parameter on the TOP Network node across all contexts.
-
New HOUDINI_DELAYSYNC_HDA environment variable that enables the delayed syncing of asset contents until the assets cook. This is available for all network types (including TOPs), and it is useful when you want to save on load/initialization time.
-
Save the global attributes that are stored on a TOP graph to its
.hipfile with the new Save Graph Attributes to .hip parameter on the TOP Network SOP node. This makes it so that when you next open the .hipfile, all the global attributes and their settings will still be available on the graph. -
Control how geometry from work items are grouped in a SOP node’s output with the new Group Work Items Using and Piece Attribute Name parameters on the
TOP Geometry SOP node. For example, you can now group geometry by Point Groups, Primitive Groups, Point Attribute, Primitive Attribute, or not group the output at all.
PDG services ¶
-
Set up and manage PDG services directly in your PDG graphs with the new Service TOP nodes:
-
 Service Create TOP node
Service Create TOP node -
 Service Start TOP node
Service Start TOP node -
 Service Stop TOP node
Service Stop TOP node -
 Service Delete TOP node
Service Delete TOP node -
 Service Reset TOP node.
Service Reset TOP node.
-
-
A new Python Script Service type is now available in the PDG Services window.
-
You can now configure a PDG service at any time during registration or after registration, but not when the service is running.
-
You can now register multiple PDG services of the same type (like multiple HDA Processor Services) and give them different names.
USD ¶
-
Control which attributes and relationships are imported from a target LOP node or
.usdfile with the new Import Attributes and Import Relationships parameters on the USD Import TOP node.
USD Import TOP node. -
Write the lists of imported attribute names and relationship names to your work item attributes with the new Attribute Names and Relationship Names parameters on the
USD Import TOP node. -
Trim tokens from USD attributes (starting from the left-hand or right-hand sides of the names) when converting them to work item attributes with the new Namespace Cutoff Index parameter on the
USD Import TOP node. -
Apply a custom file tag to all the outputs produced by the
 USD Render TOP node’s work items with the new Output File Tag parameter.
USD Render TOP node’s work items with the new Output File Tag parameter.
Networks & servers ¶
-
When retrying failed URL requests, you can now specify the time interval between retries and which HTTP status codes to retry with the new Retry Backoff and Retry Status Codes parameters on the
 URL Request TOP node.
URL Request TOP node.
Expressions ¶
-
Failed attribute evaluations like out-of-bounds indices or invalid file tags in TOP node expressions now produce explicit warning messages that describe in detail the cause of the failed evaluations.
PDG APIs ¶
-
All the PDG methods for adding, removing, and accessing attributes have been moved to the new pdg.AttributeOwner base class from pdg.WorkItem. This change does not affect existing code that accesses attributes since
pdg.WorkItemnow inherits from this new base class and all the methods are still accessible frompdg.WorkIteminstances. -
The pdg.ValuePattern class now supports a more condensed syntax for specifying a range of values by using a string prefix for each value. The range is defined by square brackets after the prefix. For example,
prefix[1-4]generates the following sequence of values:prefix1, prefix2, prefix3. The range can also include an optional step size. For example,prefix[1-10:2]. -
New pdg.AttributeUtils.ignoreWarnings() context block lets you temporarily suppress
@attribexpression warning messages caused by the lack of valid work item data. -
New prepareDirty() method for the pdg.Graph, pdg.Node, and pdg.WorkItem classes allows you to create a pdg.WorkItemDirty object. This object holds the description of a dirty operation that can be either discarded or performed at a later time.
-
New evaluateBool() method for pdg.Port lets you evaluate an integer port as a boolean.
-
The pdg.WorkItem.cookDuration() property now returns useful values at any stage of its work item’s cook. For example,
pdg.WorkItem.cookDuration()will now return0if the work item has not started to cook andcurrent_time - start_timeif the work item is in the process of cooking. -
Most
pdg.Attribute-type classes (for example, like pdg.AttributeFile and so on) now have a newisArrayproperty which is set toTruefor data types (int,float,string, andfile) that support arrays of values. -
PDG Python and Job API result data methods are now deprecated and have been replaced by new methods with names that reference input file and output file. For example, the new pdg.WorkItem.inputFiles method replaces
pdg.WorkItem.inputResultDataand the new pdg.WorkItem.outputFiles method replacespdg.WorkItem.resultData. However, all old PDG APIResultDatamethods will continue to work. -
The
pdg.utils.addItemFromSerialized(..)utility method is now deprecated. Please use the pdg.WorkItemHolder.addWorkItemFromJSONFile method instead. -
The code used to produce wrapped ROP TOP assets is now available in the
pdg.hda.ropwrappermodule. -
Query information about a node’s job script with the new pdg.Node.scriptInfo property.
-
Evaluate a PDG node parameter without applying back tick or
$variableexpansion with the new pdg.Port.evaluateRawString method. -
Python scripts can now write the pdg.File.size property. It is no longer read-only.
-
The from, to, and scheduler pdg.PathMapEntry methods have been renamed to
mapFrom,mapTo, andcreatedByrespectively.
Work items ¶
-
Specify the name of the expanded value attribute that is added to expanded file list or partition work items with the new Value Attribute parameter on the
 Work Item Expand TOP node.
Work Item Expand TOP node. -
Import work items from
.jsonfiles on disk or from other TOP nodes in your scene file (including any attribute data or output files listed on your source work items) with the new Work Item Import TOP node.
Work Item Import TOP node. -
Boost the priority of a work item on a
 Remote Graph TOP node with the new menu Boost Priority option for the work item.
Remote Graph TOP node with the new menu Boost Priority option for the work item.
Attributes ¶
-
Make attributes accessible to all the nodes in your TOP graph (
/topnet) by storing their data globally with the new global attributes. You can create global attributes directly on your graph or bind them to specific work items, and you can access global attributes with either the@attributesyntax in a scene or by using the PDG Python API. For more information, see Global vs. Work Item Attributes.-
Create global attributes with the new Scope > Graph (Bound) or Graph (Global) parameter options on the
 Attribute Create TOP node, or with either the
Attribute Create TOP node, or with either the  Python Script TOP node or the Python Processor TOP node.
Python Script TOP node or the Python Processor TOP node. -
Remove global attributes with the new Attribute Scope > Graph parameter option on the
 Attribute Delete TOP node, or with either the Python Script TOP node or the Python Processor TOP node.
Attribute Delete TOP node, or with either the Python Script TOP node or the Python Processor TOP node.
-
-
Convert between output files, intrinsic fields on work items, and attributes with the new
 Attribute Promote TOP node. You can also use this node to set global graph attributes from work item attributes, or set work item attributes from global graph attributes.
Attribute Promote TOP node. You can also use this node to set global graph attributes from work item attributes, or set work item attributes from global graph attributes. -
Reduce array attributes per work item down to a single value with the new Attribute Reduce TOP node.
Schedulers ¶
-
Set connection, timeout, and retry count options for Scheduler RPC endpoints with the new RPC Server parameters on all Scheduler nodes.
-
Specify the path to the node you want to cook when submitting a job with the new Output Node parameter on the
 HQueue Scheduler TOP,
HQueue Scheduler TOP,  Deadline Scheduler TOP, and
Deadline Scheduler TOP, and  Tractor Scheduler TOP farm scheduler nodes.
Tractor Scheduler TOP farm scheduler nodes. -
Specify how long to wait for the Scheduler’s task files before timing out with the new Task File Timeout parameter on the
Deadline Scheduler TOP node. -
Prevent Houdini packages from being loaded into child processes created by the Local Scheduler with the new Skip Loading Packages parameter on the
 Local Scheduler TOP node. You can also add this parameter to individual nodes that use the Local Scheduler as a Schedulers tab ▸ TOP Scheduler Override.
Local Scheduler TOP node. You can also add this parameter to individual nodes that use the Local Scheduler as a Schedulers tab ▸ TOP Scheduler Override. -
HQueue Scheduler TOP node now automatically sets
HOUDINI_MAXTHREADSso that it matches the current CPUs per Job parameter value unless the Max Threads parameter is explicitly set. However, if CPUs per Job is not set, thenHOUDINI_MAXTHREADSwill default to 0 and each farm jobs will be allowed to use all CPU cores. -
HQueue Scheduler TOP node now automatically applies the single Job Parms > Tags to any jobs that do not have an explicitly set CPUs per Job parameter value.
-
Automatically retry child tasks when their parent tasks are retried manually with the new Auto retry downstream tasks parameter on the
Tractor Scheduler node.
Processors ¶
-
All Processor nodes that schedule work items now have a new Schedule When parameter. This parameter allows you to specify whether or not a given work item is scheduled, or use an expression to conditionally turn on/off the scheduling of a given work item.
-
Choose whether to cook your Processor work items in-process or out-of-process with the parameters listed below.
View parameters
-
Cook Type parameter on:
-
 ImageMagick TOP node
ImageMagick TOP node -
 HDA Processor TOP node
HDA Processor TOP node -
USD Render TOP node
-
 File Copy TOP node
File Copy TOP node -
 File Decompress TOP node
File Decompress TOP node -
 File Compress TOP node
File Compress TOP node -
 ROP Fetch TOP node
ROP Fetch TOP node -
 ROP Geometry TOP node
ROP Geometry TOP node -
 ROP FBX Output TOP node
ROP FBX Output TOP node -
 ROP Mantra TOP node
ROP Mantra TOP node -
 ROP Karma TOP node
ROP Karma TOP node -
ROP USD TOP node
-
 ROP Alembic TOP node
ROP Alembic TOP node -
 ROP Composite TOP node.
ROP Composite TOP node.
-
Rename During parameter on the
 File Rename TOP node.
File Rename TOP node. -
Download File(s) During parameter on the
 Download File TOP node.
Download File TOP node. -
Evaluate Errors During parameter on the
 Error TOP node.
Error TOP node. -
Remove During parameter on the
 Remove File TOP node.
Remove File TOP node. -
Write During parameter on the
 Text Output TOP node.
Text Output TOP node. -
Perform Request During parameter on the
URL Request TOP node. -
Evaluate Script During on the
Python Script TOP node.
When a work item cooks in-process, it cooks within the current Houdini session (main thread). When a work item cooks out-of-process, it is cooked by a separate process that is created by a Scheduler. Cooking work items in-process is a lot faster than cooking them out-of-process, but it is only appropriate for small lightweight HDAs. For example, you do not want to spin up new tasks on the farm just to cook a lightweight HDA that performs a quick operation on the output of a larger simulation.
-
-
Cook your Processor work items using a service with the new Service cook type parameter option and Service Name parameter on the following nodes:
-
Python Script TOP node
-
ImageMagick TOP node
-
 Perforce TOP node
Perforce TOP node -
Render IFD TOP node
-
USD Render TOP node.
-
-
Use a custom Python script to filter render outputs and report them as work item output files with the new Output Filter parameter on the
Render IFD TOP node. -
For work items cooked in-process, you can now reuse existing
.hdainstances instead of creating/destroying fresh instances for each cook with the new Delete HDA Instance after Cooking parameter on the HDA Processor TOP node. -
Use a specific operator type or the first definition found in a target
.hdawith the new Specify Operator Using > First Definition in Asset and Custom String parameter options and Operator Type parameter on the HDA Processor TOP node. -
Rename upstream output files with the new Upstream Output File option for the File Source parameter on the
File Rename TOP node. -
Control how your archive files are compressed with the new compression controls on the
File Compress TOP node.-
Turn compression on or off for
.zipfiles with the new Compress Archive parameter. -
Append files to an existing
.zipfile on disk with the new Append to Existing Archive parameter. -
Specify the level of compression for
.tar.gzfiles with the new Compression Level parameter.
-
-
Customize the labels for your
 Output TOP node work items with the new Work Item Label parameter and options.
Output TOP node work items with the new Work Item Label parameter and options. -
 OP Notify TOP node can now trigger a Reload button on its target TOP node when work items on that node cook.
OP Notify TOP node can now trigger a Reload button on its target TOP node when work items on that node cook. -
Store matching files to a work item attribute instead of as work item output files with the new Output Attribute parameters on the
 File Pattern TOP node.
File Pattern TOP node. -
When other columns have a numeric suffix, the column headers produced by the
 CSV Output TOP node now include a numeric suffix for the 0th value of an attribute. Additionally, columns with a numeric suffix now also use the same format as the
CSV Output TOP node now include a numeric suffix for the 0th value of an attribute. Additionally, columns with a numeric suffix now also use the same format as the @attribaccessor. For example, writing out an attribute namedscalewith three components would produce the CSV column names:scale.0,scale.1andscale.2. -
Specify columns using an attribute pattern with the new Attribute Pattern parameter on the
CSV Output TOP node. -
Python Script TOP node now runs its script code during work item generation by default. You also still have the option to run the script code during the node’s in-process cook.
-
Specify whether or not a script parameter is evaluated with variable expansion or as a raw string with the new Expand Variables in Script parameter on the
Python Script TOP node. -
Select a cache mode for your scripts and specify where their output files will come from with the new Caching and Output Files parameters on the
Python Script TOP node. These parameters allow you to cook work items from cache when their outputs are already found on disk. -
When a
Python Processor TOP node needs to read the contents of input files to be able to generate its work items, you can now turn on the new Requires Input Data parameter on the node to indicate that it requires access to input file data. -
Control how attribute name conflicts should be resolved when loading work item
.jsondata with the new On Attribute Collision parameter on the JSON Input TOP node.
JSON Input TOP node. -
Write partition contents to JSON as an array of work items with the new Write Partition Contents parameter on the
 JSON Output TOP node.
JSON Output TOP node.
Partitioners ¶
-
Preserve the array size of incoming attributes when they are merged by Partitioners with the new Preserve Arrays parameter on most Partitioner nodes.
-
The Merge Operations multiparm on Partitioner nodes is now produced by the pdg.mergeOperationMenu() function instead of manually specifying its settings in each Partitioner node’s parameter interface.
-
Sort nodes by name or input index with the new Sort Nodes By parameter on the
 Partition by Node TOP node.
Partition by Node TOP node.
ROP workflows ¶
-
Choose whether to cook your work items in-process, out-of-process, or using a service with the new Cook Type parameter options on all the ROP TOP nodes. You can use this for cooking both single frame and batch work items, but not for cooking ROPs in external
.hipfiles or distributed sims. -
Specify which service you want to use to cook your ROP TOP nodes with the new Service Name parameter.
-
Choose to ignore errors when work items load their scene files with the new Ignore Scene Load Errors parameter on all the ROP TOP nodes.
-
Start your batches only once a specific number or percentage of frames have cooked with the new Fixed Number of Frames are Ready and Percentage of Frames are Ready options for the Cook Batch When parameter on all the ROP TOP nodes.
-
Control whether or not work items should look for output log messages and specify a format string for those message with the new Output Log Parsing and Custom Log Format parameters all the ROP TOP nodes.
-
Generate work items that cook an
FBX ROP and output .fbxfiles with the new ROP FBX Output TOP node. -
Set-up your
ROP Karma TOP nodes with greater ease with the new simplified Karma parameters. For more information, see the Solaris v19.5 What’s New. -
Customize the labels for your
ROP Karma TOP node work items with the new Work Item Label parameter and options. -
Specify the path to a parameter that should be pressed before each frame cook with the new Reload Parm Path parameter on the the
ROP Fetch TOP and ROP Geometry TOP nodes. This is helpful when cooking a ROP that references nodes that need to manually reload external resources with a Reload button. -
ROP Fetch TOP node now sets its pre and post frame hooks on its target ROP using the hou.RopNode.addRenderEventCallback HOM API method instead of writing to the pre and post frame script parameters on the ROP node.